Виды выборки. Интервальное оценивание генеральной доли
Для определения вероятностей интересующих нас событий мы применяем выборочный метод : проводим n независимых экспериментов, в каждом из которых может произойти (или не произойти) событие А (вероятность р появления события А в каждом эксперименте постоянна). Тогда относительная частота p* появлений событий А в серии из n испытаний принимается в качестве точечной оценки для вероятности p появления события А в отдельном испытании. При этом величину p* называют выборочной долей появлений события А , а р - генеральной долей .
В силу следствия из центральной предельной теоремы (теорема Муавра-Лапласа) относительную частоту события при большом объеме выборки можно считать нормально распределенной с параметрами M(p*)=p и
Поэтому при n>30 доверительный интервал для генеральной доли можно построить, используя формулы:
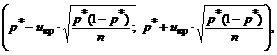
где u кр находится по таблицам функции Лапласа с учетом заданной доверительной вероятности γ: 2Ф(u кр)=γ.
При малом объеме выборки n≤30 предельная ошибка ε определяется по таблице распределения Стьюдента :
![]() где t кр =t(k; α) и число степеней свободы k=n-1 вероятность α=1-γ (двустороння область).
где t кр =t(k; α) и число степеней свободы k=n-1 вероятность α=1-γ (двустороння область).
Формулы справедливы, если отбор проводился случайным повторным образом (генеральная совокупность бесконечна), в противном случае необходимо сделать поправку на бесповторность отбора (таблица).
Средняя ошибка выборки для генеральной доли
| Генеральная совокупность | Бесконечная | Конечная объема N |
| Тип отбора | Повторный | Бесповторный |
| Средняя ошибка выборки |
Формулы расчета численности выборки при собственно-случайном способе отбора
| Способ отбора | Формулы определения численности выборки | ||
| для средней | для доли | ||
| Повторный | |||
| Бесповторный | |||
Задачи о генеральной доле
На вопрос «Накрывает ли доверительный интервал заданное значение p 0 ?» - можно ответить, проверив статистическую гипотезу H 0:p=p 0 . При этом предполагается, что опыты проводятся по схеме испытаний Бернулли (независимы, вероятность p появления события А постоянна). По выборке объема n определяют относительную частоту p * появления события A: где m - количество появлений события А в серии из n испытаний. Для проверки гипотезы H 0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).Таблица 1 - Гипотезы о генеральной доле
Гипотеза | H 0:p=p 0 | H 0:p 1 =p 2 |
| Предположения | Схема испытаний Бернулли | Схема испытаний Бернулли |
| Оценки по выборке |  |
|
| Статистика K |  | 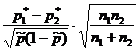 |
| Распределение статистики K | Стандартное нормальное N(0,1) |
Пример №1
. С помощью случайного повторного отбора руководство фирмы провело выборочный опрос 900 своих служащих. Среди опрошенных оказалось 270 женщин. Постройте доверительный интервал , с вероятностью 0.95 накрывающий истинную долю женщин во всем коллективе фирмы.
Решение. По условию выборочная доля женщин составляет (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
![]()
Значение u кр находим по таблице функции Лапласа из соотношения 2Ф(u кр)=γ, т.е. ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при u кр =1.96. Следовательно, предельная ошибка
Функция Лапласа (приложение 1) принимает значение 0.475 при u кр =1.96. Следовательно, предельная ошибка ![]() и искомый доверительный интервал
и искомый доверительный интервал
(p – ε, p + ε) = (0.3 – 0.18; 0.3 + 0.18) = (0.12; 0.48)
Итак, с вероятностью 0.95 можно гарантировать, что доля женщин во всем коллективе фирмы находится в интервале от 0.12 до 0.48.
Пример №2
. Владелец автостоянки считает день «удачным», если автостоянка заполнена более, чем на 80 %. В течение года было проведено 40 проверок автостоянки, из которых 24 оказались «удачными». С вероятностью 0.98 найдите доверительный интервал для оценки истинной доли «удачных» дней в течение года.
Решение
. Выборочная доля «удачных» дней составляет
По таблице функции Лапласа найдем значение u кр при заданной
доверительной вероятности
Ф(2.23) = 0.49, u кр = 2.33.
Считая отбор бесповторным (т.е. две проверки в один день не проводилось), найдем предельную ошибку: ![]()
где n=40 , N = 365 (дней). Отсюда ![]()
и доверительный интервал для генеральной доли: (p – ε, p + ε) = (0.6 – 0.17; 0.6 + 0.17) = (0.43; 0.77)
С вероятностью 0.98 можно ожидать, что доля «удачных» дней в течение года находится в интервале от 0.43 до 0.77.
Пример №3
. Проверив 2500 изделий в партии, обнаружили, что 400 изделий высшего сорта, а n–m – нет. Сколько надо проверить изделий, чтобы с уверенностью 95% определить долю высшего сорта с точностью до 0.01 ?
Решение ищем по формуле определения численности выборки для повторного отбора.
Ф(t) = γ/2 = 0.95/2 = 0.475 и этому значению по таблице Лапласа соответствует t=1.96
Выборочная доля w = 0.16; ошибка выборки ε = 0.01
Пример №4
. Партия изделий принимается, если вероятность того, что изделие окажется соответствующим стандарту, составляет не менее 0.97. Среди случайно отобранных 200 изделий проверяемой партии оказалось 193 соответствующих стандарту. Можно ли на уровне значимости α=0,02 принять партию?
Решение
. Сформулируем основную и альтернативную гипотезы.
H 0:p=p 0 =0,97 - неизвестная генеральная доля p
равна заданному значению p 0 =0,97. Применительно к условию - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, равна 0.97; т.е. партию изделий можно принять.
H 1:p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Наблюдаемое значение статистики K
(таблица) вычислим при заданных значениях p 0 =0,97, n=200, m=193

Критическое значение находим по таблице функции Лапласа из равенства
![]()
По условию α=0,02 отсюда Ф(Ккр)=0,48 и Ккр=2,05. Критическая область левосторонняя, т.е. является интервалом (-∞;-K kp)= (-∞;-2,05). Наблюдаемое значение К набл =-0,415 не принадлежит критической области, следовательно, на данном уровне значимости нет оснований отклонять основную гипотезу. Партию изделий принять можно.
Пример №5
. Два завода изготавливают однотипные детали. Для оценки их качества сделаны выборки из продукции этих заводов и получены следующие результаты. Среди 200 отобранных изделий первого завода оказалось 20 бракованных, среди 300 изделий второго завода - 15 бракованных.
На уровне значимости 0.025 выяснить, имеется ли существенное различие в качестве изготавливаемых этими заводами деталей.
По условию α=0,025 отсюда Ф(Ккр)=0,4875 и Ккр=2,24. При двусторонней альтернативе область допустимых значений имеет вид (-2,24;2,24). Наблюдаемое значение K набл =2,15 попадает в этот интервал, т.е. на данном уровне значимости нет оснований отвергать основную гипотезу. Заводы изготавливают изделия одинакового качества.
Статистические исследования очень трудоемки и дороги, поэтому возникла мысль о замене сплошного наблюдения выборочным.
Основная цель несплошного наблюдения состоит в получении характеристик изучаемой статистической совокупности по обследованной ее части.
Выборочное наблюдение – это метод статистического исследования, при котором обобщающие показатели совокупности устанавливаются только по отдельно взятой части на основе положений случайного отбора.
При выборочном методе изучению подвергается только некоторая часть изучаемой совокупности, при этом подлежащая изучению статистическая совокупность называется генеральной совокупностью.
Выборочной совокупностью или просто выборкой можно называть отобранную из генеральной совокупности часть единиц, которая будет подвергаться статистическому исследованию.
Значение выборочного метода: при минимальной численности исследуемых единиц проведение статистического исследования будет происходить в более короткие промежутки времени и с наименьшими затратами средств и труда.
В генеральной совокупности доля единиц, которая обладает изучаемым признаком, называется генеральной долей (обозначается р), а средняя величина изучаемого варьирующего признака – это генеральная средняя (обозначается х).
В выборочной совокупности долю изучаемого признака называют выборочной долей, или частью (обозначается w), средняя величина в выборке – это выборочная средняя.
Если в период обследования будут соблюдены все правила его научной организации, то выборочный метод даст довольно точны результаты, и поэтому данный метод целесообразно применять для проверки данных сплошного наблюдения.
Этот метод получил широкое распространение в государственной и вневедомственной статистике, потому что при исследовании минимальной численности изучаемых единиц позволяет тщательно и точно провести исследование.
Изучаемая статистическая совокупность состоит из единиц с варьирующими признаками. Состав выборочной совокупности может отличаться от состава генеральной совокупности, это расхождение между характеристиками выборки и генеральной совокупности составляет ошибку выборки.
Ошибки, свойственные выборочному наблюдению, характеризуют размер расхождения между данными выборочного наблюдения и всей совокупности. Ошибки, возникающие в ходе выборочного наблюдения, называются ошибками репрезентативности и делятся на случайные и систематические.
Если выборочная совокупность недостаточно точно воспроизводит всю совокупность из–за несплошного характера наблюдения, то это называют случайными ошибками, и их размеры определяются с достаточной точностью на основании закона больших чисел и теории вероятностей.
Систематические ошибки возникают в результате нарушения принципа случайности отбора единиц совокупности для наблюдения.
2. Виды и схемы отбора
Размер ошибки выборки и методы ее определения зависят от вида и схемы отбора.
Различают четыре вида отбора совокупности единиц наблюдения:
1) случайный;
2) механический;
3) типический;
4) серийный (гнездовой).
Случайный отбор – наиболее распространенный способ отбора в случайной выборке, его еще называют методом жеребьевки, при нем на каждую единицу статистической совокупности заготовляется билет с порядковым номером.
Далее в случайном порядке отбирается необходимое количество единиц статистической совокупности. При этих условиях каждая из них имеет одинаковую вероятность попасть в выборку, например тиражи выигрышей, когда из общего количества выпущенных билетов в случайном порядке наугад отбирается определенная часть номеров, на которые приходятся выигрыши. При этом всем номерам обеспечивается равная возможность попасть в выборку.
Механический отбор – это способ, когда вся совокупность разбивается на однородные по объему группы по случайному признаку, потом из каждой группы берется только одна единица Все единицы изучаемой статистической совокупности предварительно располагаются в определенном порядке, но в зависимости от объема выборки механически через определенный интервал отбирается необходимое количество единиц.
Типический отбор – это способ, при котором исследуемая статистическая совокупность разбивается по существенному, типическому признаку на качественно однородные, однотипные группы, затем из каждой этой группы случайным способом отбирается определенное количество единиц, пропорциональное удельному весу группы во всей совокупности.
Типический отбор дает более точные результаты, так как при нем в выборку попадают представители всех типических групп.
Серийный (гнездовой) отбор. Отбору подлежат целые группы (серии, гнезда), отобранные случайным или механическим способом. По каждой такой группе, серии проводится сплошное наблюдение, а результаты переносятся на всю совокупность.
Точность выборки зависит и от схемы отбора. Выборка может быть проведена по схеме повторного и бесповторного отбора.
Повторный отбор. Каждая отобранная единица или серия возвращается во всю совокупность и может вновь попасть в выборку Это так называемая схема возвращенного шара.
Бесповторный отбор. Каждая обследованная единица изымается и не возвращается в совокупность, поэтому она не попадает в повторное обследование. Эта схема получила название невозвращенного шара.
Бесповторный отбор дает более точные результаты, потому что при одном и том же объеме выборки наблюдение охватывает большее количество единиц изучаемой совокупности.
Комбинированный отбор может проходить одну или несколько ступеней. Выборка называется одноступенчатой, если отобранные однажды единицы совокупности подвергаются изучению.
Выборка называется многоступенчатой, если отбор совокупности проходит по ступеням, последовательным стадиям, причем каждая ступень, стадия отбора имеет свою единицу отбора.
Многофазная выборка – на всех ступенях выборки сохраняется одна и та же единица отбора, но проводится несколько стадий, фаз выборочных обследований, которые различаются между собой широтой программы обследования и объемом выборки.
Характеристики параметров генеральной и выборочной совокупностей обозначаются следующими символами:
N – объем генеральной совокупности;
n – объем выборки;
X – генеральная средняя;
х – выборочная средняя;
р – генеральная доля;
w – выборочная доля;
2 – генеральная дисперсия (дисперсия признака в генеральной совокупности);
2 – выборочная дисперсия того же признака;
?– среднее квадратическое отклонение в генеральной совокупности;
?– среднее квадратическое отклонение в выборке.
3. Ошибки выборки
Каждая единица при выборочном наблюдении должна иметь равную с другими возможность быть отобранной – это является основой собственнослучайной выборки.
Собственнослучайная выборка – это отбор единиц из всей генеральной совокупности посредством жеребьевки или другим подобным способом.
Принципом случайности является то, что на включение или исключение объекта из выборки не может повлиять любой фактор, кроме случая.
Доля выборки – это отношение числа единиц выборочной совокупности к числу единиц генеральной совокупности:
Собственнослучайный отбор в чистом виде является исходным среди всех других видов отбора, в нем заключаются и реализуются основные принципы выборочного статистического наблюдения.
Два основных вида обобщающих показателей, которые используют в выборочном методе – это средняя величина количественного признака и относительная величина альтернативного признака.
Выборочная доля (w), или частность, определяется отношением числа единиц, обладающих изучаемым признаком m, к общему числу единиц выборочной совокупности (n):
Для характеристики надежности выборочных показателей различают среднюю и предельную ошибки выборки.
Ошибка выборки, ее еще называют ошибкой репрезентативности, представляет собой разность соответствующих выборочных и генеральных характеристик:
?х =|х – х|;
?w =|х – p|.
Только выборочным наблюдениям присуща ошибка выборки
Выборочная средняя и выборочная доля – это случайные величины, принимающие различные значения в зависимости от единиц изучаемой статистической совокупности, которые попали в выборку. Соответственно ошибки выборки – тоже случайные величины и также могут принимать различные значения. Поэтому определяют среднюю из возможных ошибок – среднюю ошибку выборки.
Средняя ошибка выборки определяется объемом выборки: чем больше численность при прочих равных условиях, тем меньше величина средней ошибки выборки. Охватывая выборочным обследованием все большее количество единиц генеральной совокупности, все более точно характеризуем всю генеральную совокупность.
Средняя ошибка выборки зависит от степени варьирования изучаемого признака, в свою очередь степень варьирования характеризуется дисперсией? 2 или w(l – w) – для альтернативного признака. Чем меньше вариация признака и дисперсия, тем меньше средняя ошибка выборки, и наоборот.
При случайном повторном отборе средние ошибки теоретически рассчитывают по следующим формулам:
1) для средней количественного признака:
где? 2 – средняя величина дисперсии количественного признака.
2) для доли (альтернативного признака):
Так как дисперсия признака в генеральной совокупности? 2 точно неизвестна, на практике пользуются значением дисперсии S 2 , рассчитанным для выборочной совокупности на основании закона больших чисел, согласно которому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности.
Формулы средней ошибки выборки при случайном повторном отборе следующие. Для средней величины количественного признака: генеральная дисперсия выражается через выборную следующим соотношением:
где S 2 – значение дисперсии.
Механическая выборка – это отбор единиц в выборочную совокупность из генеральной, которая разбита по нейтральному признаку на равные группы; производится так, что из каждой такой группы в выборку отбирается лишь одна единица.
При механическом отборе единицы изучаемой статистической совокупности предварительно располагают в определенном порядке, после чего отбирают заданное число единиц механически через определенный интервал. При этом размер интервала в генеральной совокупности равен обратному значению доли выборки.
При достаточно большой совокупности механический отбор по точности результатов близок к собственнослучайному Поэтому для определения средней ошибки механической выборки используют формулы собственнослучайной бесповторной выборки.
Для отбора единиц из неоднородной совокупности применяется так называемая типическая выборка, используется, когда все единицы генеральной совокупности можно разбить на несколько качественно однородных, однотипных групп по признакам, от которых зависят изучаемые показатели.
Затем из каждой типической группы собственнослучайной или механической выборкой производится индивидуальный отбор единиц в выборочную совокупность.
Типическая выборка обычно применяется при изучении сложных статистических совокупностей.
Типическая выборка дает более точные результаты. Типизация генеральной совокупности обеспечивает репрезентативность такой выборки, представительство в ней каждой типологической группы, что позволяет исключить влияние межгрупповой дисперсии на среднюю ошибку выборки. Поэтому при определении средней ошибки типической выборки в качестве показателя вариации выступает средняя из внутригрупповых дисперсий.
Серийная выборка предполагает случайный отбор из генеральной совокупности равновеликих групп для того, чтобы в таких группах подвергать наблюдению все без исключения единицы.
Поскольку внутри групп (серий) обследуются все без исключения единицы, средняя ошибка выборки (при отборе равновеликих серий) зависит только от межгрупповой (межсерийной) дисперсии.
4. Способы распространения выборочных результатов на генеральную совокупность
Характеристика генеральной совокупности на основе выборочных результатов – это конечная цель выборочного наблюдения.
Выборочный метод применяется для получения характеристик генеральной совокупности по определенным показателям выборки. В зависимости от целей исследования это осуществляется прямым пересчетом показателей выборки для генеральной совокупности или методом расчета поправочных коэффициентов.
Способ прямого пересчета в том, что при нем показатели выборочной доли w или средней х распространяются на генеральную совокупность с учетом ошибки выборки.
Способ поправочных коэффициентов применяется, когда целью выборочного метода является уточнение результатов сплошного учета. Данный способ используется при уточнении данных ежегодных переписей скота у населения.
Тема: Выборочный метод в статистике
1. Понятие о выборочном наблюдении, его задачи
Статистическое наблюдение можно организовать сплошное и несплошное. Сплошное наблюдение предусматривает обследование всех единиц изучаемой совокупности и связано с большими трудовыми и материальными затратами. Изучение не всех единиц совокупности, а лишь некоторой части, по которой следует судить о свойствах всей совокупности в целом, можно осуществить несплошным наблюдением. В статистической практике самым распространенным является выборочное наблюдение.
Выборочное наблюдение - это такой вид несплошного наблюдения, при котором отбор подлежащих обследованию единиц осуществляется в случайном порядке, отобранная часть изучается, а результаты распространяются на всю исходную совокупность. Наблюдение организуется таким образом, что эта часть отобранных единиц в уменьшенном масштабе репрезентирует (представляет) всю совокупность.
Совокупность, из которой производится отбор, называется генеральной, генеральными.
Совокупность отобранных единиц именуют выборочной совокупностью, и все ее обобщающие показатели - выборочными.
Имеется ряд причин, в силу которых, во многих случаях выборочному наблюдению отдается предпочтение перед сплошным. Наиболее существенны из них следующие:
Экономия времени и средств в результате сокращения объема работы;
Сведение к минимуму порчи или уничтожения исследуемых объектов (определение прочности пряжи при разрыве, испытание электрических лампочек на продолжительность горения, проверка консервов на доброкачественность);
Необходимость детального исследования каждой единицы наблюдения при невозможности охвата всех единиц (при изучении бюджета семей);
Достижение большой точности результатов обследования благодаря сокращению ошибок, происходящих при регистрации.
Преимущество выборочного наблюдения по сравнению со сплошным можно реализовать, если оно организовано и проведено в строгом соответствии с научными принципами теории выборочного метода. Такими принципами являются: обеспечение случайности (равной возможности попадания в выборку) отбора единиц и достаточного их числа. Соблюдение этих принципов позволяет получить объективную гарантию репрезентативности полученной выборочной совокупности. Понятие репрезентативности отобранной совокупности не следует понимать как ее представительство по всем признакам изучаемой совокупности, а только в отношении тех признаков, которые изучаются или оказывают существенное влияние на формирование сводных обобщающих характеристик.
Основная задача выборочного наблюдения в экономике состоит в том, чтобы на основе характеристик выборочной совокупности (средней и доли) получить достоверные суждения о показателях средней и доли в генеральной совокупности. При этом следует иметь в виду, что при любых статистических исследованиях (сплошных и выборочных) возникают ошибки двух видов: регистрации и репрезентативности.
Ошибки регистрации могут иметь случайный (непреднамеренный) и систематический (тенденциозный) характер. Случайные ошибки обычно уравновешивают друг друга, поскольку не имеют преимущественного направления в сторону преувеличения или преуменьшения значения изучаемого показателя. Систематические ошибки направлены в одну сторону вследствие преднамеренного нарушения правил отбора (предвзятые цели). Их можно избежать при правильной организации и проведении наблюдения.
Ошибки репрезентативности присущи только выборочному наблюдению и возникают в силу того, что выборочная совокупность не полностью воспроизводит генеральную. Они представляют собой расхождение между значениями показателей, полученных по выборке, и значениями показателей этих же величин, которые были бы получены при проведенном с одинаковой степенью точности сплошном наблюдении, т. е. между величинами выборных и соответствующих генеральных показателей.
Для каждого конкретного выборочного наблюдения значение ошибки репрезентативности может быть определено по соответствующим формулам, которые зависят от вида, метода и способа формирования выборочной совокупности.
По виду различают индивидуальный, групповой и комбинированный отбор. При индивидуальном отборе в выборочную совокупность отбираются отдельные единицы генеральной совокупности; при групповом отборе - качественно однородные группы или серии изучаемых единиц; комбинированный отбор предполагает сочетание первого и второго видов.
По методу отбора различают повторную и бесповторную выборки.
При повторной выборке общая численность единиц генеральной совокупности в процессе выборки остается неизменной. Ту или иную единицу, попавшую в выборку, после регистрации снова возвращают в генеральную совокупность, и она сохраняет равную возможность со всеми прочими единицами при повторном отборе единиц вновь попасть в выборку («отбор по схеме возвращенного шара»). Повторная выборка в социально-экономической жизни встречается редко. Обычно выборку организуют по схеме бесповторной выборки.
При бесповторной выборке единица совокупности, попавшая в выборку, в генеральную совокупность не возвращается и в дальнейшем в выборке не участвует; т. е. последующую выборку делают из генеральной совокупности уже без отобранных ранее единиц («отбор по схеме невозвращенного шара»). Таким образом, при бесповторной выборке численность единиц генеральной совокупности сокращается в процессе исследования.
Способ отбора определяет конкретный механизм или процедуру выборки единиц из генеральной совокупности.
По степени охвата единиц совокупности различают большие и малые (n <30) выборки.
В практике выборочных исследований наибольшее распространение получили следующие виды выборки: собственно-случайная, механическая, типическая, серийная, комбинированная.
Основные характеристики параметров генеральной и выборочной совокупностей обозначаются символами:
N-объем генеральной совокупности (число входящих в нее единиц);
п - объем выборки (число обследованных единиц);
- генеральная средняя (среднее значение признака в генеральной совокупности);
- выборочная средняя;P - генеральная доля (доля единиц, обладающих данным значением признака в общем числе единиц генеральной совокупности);
w - выборочная доля;
- генеральная дисперсия (дисперсия признака в генеральной совокупности);
S 2 - выборочная дисперсия того же признака;
- среднее квадратическое отклонение в генеральной совокупности;
S - среднее квадратическое отклонение в выборке.
2. Ошибки выборки
При выборочном наблюдении должна быть обеспечена случайность отбора единиц. Каждая единица должна иметь равную с другими возможность быть отобранной. Именно на этом основывается собственно-случайная выборка.
К собственно-случайной выборке относится отбор единиц из всей генеральной совокупности (без предварительного расчленения ее на какие-либо группы) посредством жеребьевки (преимущественно) или какого-либо иного подобного способа, например, с помощью таблицы случайных чисел. Случайный отбор - это отбор не беспорядочный. Принцип случайности предполагает, что на включение или исключение объекта из выборки не может повлиять какой-либо фактор, кроме случая. Примером собственно-случайного отбора могут служить тиражи выигрышей: из общего количества выпущенных билетов наугад отбирается определенная часть номеров, на которые приходятся выигрыши. Причем всем номерам обеспечивается равная возможность попадания в выборку. При этом количество отобранных в выборочную совокупность единиц обычно определяется исходя из принятой доли выборки.
Доля, выборки есть отношение числа единиц выборочной совокупности к числу единиц генеральной совокупности:
Так, при 5%-ной выборке из партии деталей в 1000 ед. объем выборки п составляет 50 ед., а при 10%-ной выборке -100 ед. и т.д. При правильной научной организации выборки ошибки репрезентативности можно свести к минимальном значениям, в результате - выборочное наблюдение становится достаточно точным.
Собственно-случайный отбор «в чистом виде» применяется в практике выборочного наблюдения редко, но он является исходным среди всех других видов отбора, в нем заключаются и реализуются основные принципы выборочного наблюдения.
Рассмотрим некоторые вопросы теории выборочного метода и формулы ошибок для простой случайной выборки.
Применяя выборочный метод в статистике, обычно используют два основных вида обобщающих показателей: среднюю величину количественного признака и относительную величину альтернативного признака (долю или удельный вес единиц в статистической совокупности, которые отличаются от всех других единиц этой совокупности только наличием изучаемого признака).
Выборочная доля ( w ), или частость, определяется отношением числа единиц, обладающих изучаемым признаком т, к общему числу единиц выборочной совокупности п:
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков (пол, возраст, доход, численность, оборот и т.д.), ограниченная в пространстве и времени. Примеры генеральных совокупностей
- Все жители Москвы (10,6 млн. человек по данным переписи 2002 года)
- Мужчины-Москвичи (4,9 млн. человек по данным переписи 2002 года)
- Юридические лица России (2,2 млн. на начало 2005 года)
- Розничные торговые точки, осуществляющие продажу продуктов питания (20 тысяч на начало 2008 года) и т.д.
Выборка (Выборочная совокупность)
Часть объектов из генеральной совокупности, отобранных для изучения, с тем чтобы сделать заключение обо всей генеральной совокупности. Для того чтобы заключение, полученное путем изучения выборки, можно было распространить на всю генеральную совокупность, выборка должна обладать свойством репрезентативности.
Репрезентативность выборки
Свойство выборки корректно отражать генеральную совокупность. Одна и та же выборка может быть репрезентативной и
нерепрезентативной для разных генеральных совокупностей.
Пример:
- Выборка, целиком состоящая из москвичей, владеющих автомобилем, не репрезентирует все население Москвы.
- Выборка из российских предприятий численностью до 100 человек не репрезентирует все предприятия России.
- Выборка из москвичей, совершающих покупки на рынке, не репрезентирует покупательское поведение всех москвичей.
В то же время, указанные выборки (при соблюдении прочих условий) могут отлично репрезентировать
москвичей-автовладельцев, небольшие и средние российские предприятия и покупателей, совершающих покупки на рынках
соответственно.
Важно понимать, что репрезентативность выборки и ошибка выборки – разные явления. Репрезентативность, в отличие от
ошибки никак не зависит от размера выборки.
Пример:
Как бы мы не увеличивали количество опрошенных москвичей-автовладельцев, мы не сможем репрезентировать этой выборкой
всех москвичей.
Ошибка выборки (доверительный интервал)
Отклонение результатов, полученных с помощью выборочного наблюдения от истинных данных генеральной совокупности.
Ошибка выборки бывает двух видов – статистическая и систематическая. Статистическая ошибка зависит от размера
выборки. Чем больше размер выборки, тем она ниже.
Пример:
Для простой случайной выборки размером 400 единиц максимальная статистическая ошибка (с 95% доверительной
вероятностью) составляет 5%, для выборки в 600 единиц – 4%, для выборки в 1100 единиц – 3% Обычно, когда говорят об
ошибке выборки, подразумевают именно статистическую ошибку.
Систематическая ошибка зависит от различных факторов, оказывающих постоянное воздействие на исследование и смещающих
результаты исследования в определенную сторону.
Пример:
- Использование любых вероятностных выборок занижает долю людей с высоким доходом, ведущих активный образ жизни. Происходит это в силу того, что таких людей гораздо сложней застать в каком-либо определенном месте (например, дома).
- Проблема респондентов, отказывающихся отвечать на вопросы (доля «отказников» в Москве, для разных опросов, колеблется от 50% до 80%)
В некоторых случаях, когда известны истинные распределения, систематическую ошибку можно нивелировать введением квот или перевзвешиванием данных, но в большинстве реальных исследований даже оценить ее бывает достаточно проблематично.
Типы выборок
Выборки делятся на два типа:
- вероятностные
- невероятностные
1. Вероятностные выборки
1.1 Случайная выборка (простой случайный отбор)
Такая выборка предполагает однородность генеральной совокупности, одинаковую вероятность доступности всех элементов,
наличие полного списка всех элементов. При отборе элементов, как правило, используется таблица случайных чисел.
1.2 Механическая (систематическая) выборка
Разновидность случайной выборки, упорядоченная по какому-либо признаку (алфавитный порядок, номер телефона, дата
рождения и т.д.). Первый элемент отбирается случайно, затем, с шагом ‘n’ отбирается каждый ‘k’-ый элемент. Размер
генеральной совокупности, при этом – N=n*k
1.3 Стратифицированная (районированная)
Применяется в случае неоднородности генеральной совокупности. Генеральная совокупность разбивается на группы
(страты). В каждой страте отбор осуществляется случайным или механическим образом.
1.4 Серийная (гнездовая или кластерная) выборка
При серийной выборке единицами отбора выступают не сами объекты, а группы (кластеры или гнёзда). Группы отбираются
случайным образом. Объекты внутри групп обследуются сплошняком.
2.Невероятностные выборки
Отбор в такой выборке осуществляется не по принципам случайности, а по субъективным критериям – доступности,
типичности, равного представительства и т.д..
2.1. Квотная выборка
Изначально выделяется некоторое количество групп объектов (например, мужчины в возрасте 20-30 лет, 31-45 лет и 46-60
лет; лица с доходом до 30 тысяч рублей, с доходом от 30 до 60 тысяч рублей и с доходом свыше 60 тысяч рублей) Для
каждой группы задается количество объектов, которые должны быть обследованы. Количество объектов, которые должны
попасть в каждую из групп, задается, чаще всего, либо пропорционально заранее известной доле группы в генеральной
совокупности, либо одинаковым для каждой группы. Внутри групп объекты отбираются произвольно. Квотные выборки
используются в достаточно
часто.
2.2. Метод снежного кома
Выборка строится следующим образом. У каждого респондента, начиная с первого, просятся контакты его друзей, коллег,
знакомых, которые подходили бы под условия отбора и могли бы принять участие в исследовании. Таким образом, за
исключением первого шага, выборка формируется с участием самих объектов исследования. Метод часто применяется, когда
необходимо найти и опросить труднодоступные группы респондентов (например, респондентов, имеющих высокий доход,
респондентов, принадлежащих к одной профессиональной группе, респондентов, имеющих какие-либо схожие хобби/увлечения
и т.д.)
2.3 Стихийная выборка
Опрашиваются наиболее доступные респонденты. Типичные примеры стихийных выборок – в газетах/журналах, отданные респондентам на самозаполнение, большинство
интернет-опросов. Размер и состав стихийных выборок заранее не известен, и определяется только одним параметром –
активностью респондентов.
2.4 Выборка типичных случаев
Отбираются единицы генеральной совокупности, обладающие средним (типичным) значением признака. При этом возникает
проблема выбора признака и определения его типичного значения.
Курс лекций по теории статистики
Более подробную информацию по выборочным наблюдениям можно получить просмотрев .
План:
1. Задачи математической статистики.
2. Виды выборок.
3. Способы отбора.
4. Статистическое распределение выборки.
5. Эмпирическая функция распределения.
6. Полигон и гистограмма.
7. Числовые характеристики вариационного ряда.
8. Статистические оценки параметров распределения.
9. Интервальные оценки параметров распределения.
1. Задачи и методы математической статистики
Математическая статистика - это раздел математики, посвященный методам сбора, анализа и обработки результатов статистических данных наблюдений для научных и практических целей.
Пусть требуется изучить совокупность однородных объектов относительно некоторого качественного или количественного признака, характеризующего эти объекты. Например, если имеется партия деталей, то качественным признаком может служить стандартность детали, а количественным- контролируемый размер детали.
Иногда проводят сплошное исследование, т.е. обследуют каждый объект относительно нужного признака. На практике сплошное обследование применяется редко. Например, если совокупность содержит очень большое число объектов, то провести сплошное обследование физически невозможно. Если обследование объекта связано с его уничтожением или требует больших материальных затрат, то проводить сплошное обследование не имеет смысла. В таких случаях случайно отбирают из всей совокупности ограниченное число объектов (выборочную совокупность) и подвергают их изучению.
Основная задача математической статистики заключается в исследовании всей совокупности по выборочным данным в зависимости от поставленной цели, т.е. изучение вероятностных свойств совокупности: закона распределения, числовых характеристик и т.д. для принятия управленческих решений в условиях неопределенности.
2. Виды выборок
Генеральная совокупность – это совокупность объектов, из которой производится выборка.
Выборочная совокупность (выборка) – это совокупность случайно отобранных объектов.
Объем совокупности – это число объектов этой совокупности. Объем генеральной совокупности обозначается N , выборочной – n .
Пример:
Если из 1000 деталей отобрано для обследования 100 деталей, то объем генеральной совокупности N = 1000, а объем выборки n = 100.
Присоставлении выборки можно поступить двумя способами: после того, как объект отобран и над ним произведено наблюдение, он может быть возвращен либо не возвращен в генеральную совокупность. Т.о. выборки делятся на повторные и бесповторные.
Повторной называют выборку , при которой отобранный объект (перед отбором следующего) возвращается в генеральную совокупность.
Бесповторной называют выборку , при которой отобранный объект в генеральную совокупность не возвращается.
На практике обычно пользуются бесповторным случайным отбором.
Для того, чтобы по данным выборки можно было достаточно уверенно судить об интересующем признаке генеральной совокупности, необходимо, чтобы объекты выборки правильно его представляли. Выборка должна правильно представлять пропорции генеральной совокупности. Выборка должна быть репрезентативной (представительной).
В силу закона больших чисел можно утверждать, что выборка будет репрезентативной, если ее осуществлять случайно.
Если объем генеральной совокупности достаточно велик, а выборка составляет лишь незначительную часть этой совокупности, то различие между повторной и бесповторной выборками стирается; в предельном случае, когда рассматривается бесконечная генеральная совокупность, а выборка имеет конечный объем, это различие исчезает.
Пример:
В американском журнале
«Литературное обозрение» с помощью статистическихметодов было проведено исследование прогнозов
относительно исхода предстоящих выборов президента США в 1936 году.
Претендентами на этот пост были Ф.Д. Рузвельт и А. М. Ландон. В качестве
источника для генеральной совокупности исследуемых американцев были взяты
справочники телефонных абонентов. Из них случайным образом были выбраны 4
миллиона адресов., по которым редакция журнала разослала открытки с просьбой
высказать свое отношение к кандидатам на пост президента. Обработав результаты
опроса, журнал опубликовал социологический прогноз о том, что на предстоящих
выборах с большим перевесом победит Ландон. И … ошибся: победу одержал
Рузвельт.
Этот пример можно рассматривать, как пример нерепрезентативной выборки. Дело в
том, что в США в первой половине двадцатого века телефоны имела лишь зажиточная
часть населения, которые поддерживали взгляды Ландона.
3. Способы отбора
На практике применяются различные способы отбора, которые можно разделить на 2 вида:
1. Отбор не требует расчленения генеральной совокупности на части (а) простой случайный бесповторный ; б) простой случайный повторный ).
2. Отбор, при котором генеральная совокупность разбивается на части. (а) типичный отбор ; б) механический отбор ; в) серийный отбор ).
Простым случайным называют такой отбор , при котором объекты извлекаются по одному из всей генеральной совокупности (случайно).
Типичным называют отбор , при котором объекты отбираются не из всей генеральной совокупности, а из каждой ее «типичной» части. Например, если деталь изготавливают на нескольких станках, то отбор производят не из всей совокупности деталей, произведенных всеми станками, а из продукции каждого станка в отдельности. Таким отбором пользуются тогда, когда обследуемый признак заметно колеблется в различных «типичных» частях генеральной совокупности.
Механическим называют отбор , при котором генеральную совокупность «механически» делят на столько групп, сколько объектов должно войти в выборку, а из каждой группы отбирают один объект. Например, если нужно отобрать 20 % изготовленных станком деталей, то отбирают каждую 5-ую деталь; если требуется отобрать 5 % деталей- каждую 20-ую и т.д. Иногда такой отбор может не обеспечивать репрезентативность выборки (если отбирают каждый 20-ый обтачиваемый валик, причем сразу же после отбора производится замена резца, то отобранными окажутся все валики, обточенные затупленными резцами).
Серийным называют отбор , при котором объекты отбирают из генеральной совокупности не по одному, а «сериями», которые подвергают сплошному обследованию. Например, если изделия изготавливаются большой группой станков-автоматов, то подвергают сплошному обследованию продукцию только нескольких станков.
На практике часто применяют комбинированный отбор, при котором сочетаются указанные выше способы.
4. Статистическое распределение выборки
Пусть из генеральной совокупности извлечена выборка, причем значение x 1 –наблюдалось раз, x 2 -n 2 раз,… x k - n k раз. n = n 1 +n 2 +...+n k – объем выборки. Наблюдаемые значения называются вариантами , а последовательность вариант, записанных в возрастающем порядке- вариационным рядом . Числа наблюдений называются частотами (абсолютными частотами) , а их отношения к объему выборки - относительными частотами или статистическими вероятностями.
Если количество вариант велико или выборка производится из непрерывной генеральной совокупности, то вариационный ряд составляется не по отдельным точечным значениям, а по интервалам значений генеральной совокупности. Такой вариационный ряд называется интервальным. Длины интервалов при этом должны быть равны.
Статистическим распределением выборки называется перечень вариант и соответствующих им частот или относительных частот.
Статистическое распределение можно задать также в виде последовательности интервалов и соответствующих им частот (суммы частот, попавших в этот интервал значений)
Точечный вариационный ряд частот может быть представлен таблицей:
|
x i |
x 1 |
x 2 |
… |
x k |
|
n i |
n 1 |
n 2 |
… |
n k |
Аналогично можно представить точечный вариационный ряд относительных частот.
Причем:
Пример:
Число букв в некотором тексте Х оказалось равным 1000. Первой встретиласьбуква «я», второй- буква «и», третьей- буква «а», четвертой- «ю». Затем шли буквы«о», «е», «у», «э», «ы».
Выпишем места, которые они занимают в алфавите, соответственно имеем: 33, 10, 1, 32, 16, 6, 21, 31, 29.
После упорядочения этих чисел по возрастанию получаем вариационный ряд: 1, 6, 10, 16, 21, 29, 31, 32, 33.
Частоты появления букв в тексте: «а» - 75, «е» -87, «и»- 75, «о»- 110, «у»- 25, «ы»- 8, «э»- 3, «ю»- 7, «я»- 22.
Составим точечный вариационный ряд частот:
Пример:
Задано распределение частот выборки объема n = 20.
Составьте точечный вариационный ряд относительных частот.
|
x i |
2 |
6 |
12 |
|
n i |
3 |
10 |
7 |
Решение:
Найдем относительные частоты:
|
x i |
2 |
6 |
12 |
|
w i |
0,15 |
0,5 |
0,35 |
При построении интервального распределения существуют правилавыбора числа интервалов или величины каждого интервала. Критерием здесь служит оптимальное соотношение: при увеличении числа интервалов улучшается репрезентативность, но увеличивается объем данных и время на их обработку. Разность x max - x min между наибольшим и наименьшим значениями вариант называют размахом выборки.
Для подсчета числа интервалов k обычно применяют эмпирическую формулу Стреджесса (подразумевая округление до ближайшего удобного целого): k = 1 + 3.322 lg n .
Соответственно, величину каждого интервала h можно вычислить по формуле :
5. Эмпирическая функция распределения
Рассмотрим некоторую выборку из генеральной совокупности. Пусть известно статистическое распределение частот количественного признака Х. Введем обозначения: n x – число наблюдений, при которых наблюдалось значение признака, меньшее х; n – общее число наблюдений (объем выборки). Относительная частота события Х<х равна n x /n . Если х изменяется, то изменяется и относительная частота, т.е. относительная частота n x /n - есть функция от х. Т.к. она находится эмпирическим путем, то она называется эмпирической.
Эмпирической функцией распределения (функцией распределения выборки) называют функцию , определяющую для каждого х относительную частоту события Х<х.
где число вариант, меньших х,
n - объем выборки.
В отличие от эмпирической функции распределения выборки, функцию распределения F (x ) генеральной совокупности называют теоретической функцией распределения .
Различие между эмпирической и
теоретической функциями распределения состоит в том, что теоретическая функция F
(x
) определяет вероятность события Х
Т.о. целесообразно использовать эмпирическую функцию распределения выборки для приближенного представления теоретической (интегральной) функции распределения генеральной совокупности.
F*(x) обладает всеми свойствами F (x ).
1. ЗначенияF*(x) принадлежат интервалу .
2. F*(x) - неубывающая функция.
3. Если – наименьшая варианта, тоF*(x) = 0, при х< x 1 ; если x k – наибольшая варианта, то F*(x) = 1, при х > x k .
Т.е. F*(x) служит для оценки F (x ).
Если выборка задана вариационным рядом, то эмпирическая функция имеет вид:
График эмпирической функции называется кумулятой.
Пример:
Постройте эмпирическую функцию по данному распределению выборки.
Решение:
Объем выборки n
= 12 + 18 +30 = 60. Наименьшая
варианта 2, т.е. при х <
2. Событие X
<6,
(x 1
= 2) наблюдалось 12 раз, т.е. F*(x)=12/60=0,2
при 2 <
x
<
6. Событие Х<10, (x 1 =2, x 2 = 6) наблюдалось 12 + 18 = 30 раз, т.е.F*(x)=30/60=0,5
при 6 <
x
<
10. Т.к. х=10 наибольшая варианта, тоF*(x) = 1
при х>10. Искомая эмпирическая функция имеет вид:
Кумулята:
Кумулята дает возможность понимать графически представленную информацию, например, ответить на вопросы: «Определите число наблюдений, при которых значение признака было меньше 6 или не меньше 6. F*(6) =0,2 » Тогда число наблюдений, при которых значение наблюдаемого признака было меньше 6 равно 0,2* n = 0,2*60 = 12. Число наблюдений, при которых значение наблюдаемого признака было не меньше 6 равно (1-0,2)* n = 0,8*60 = 48.
Если задан интервальный вариационный ряд, то для составления эмпирической функции распределения находят середины интервалов и по ним получают эмпирическую функцию распределения аналогично точечному вариационному ряду.
6. Полигон и гистограмма
Для наглядности строят различные графики статистического распределения: полином и гистограммы
Полигон частот- это ломаная, отрезки которой соединяют точки ( x 1 ;n 1 ), ( x 2 ;n 2 ),…, ( x k ; n k ), где – варианты, – соответствующие им частоты.
Полигон относительных частот- это ломаная, отрезки которой соединяют точки ( x 1 ;w 1 ), (x 2 ;w 2 ),…, ( x k ;w k ), гдеx i –варианты, w i – соответствующие им относительные частоты.
Пример:
Постройте полином относительных частот по данному распределению выборки:
Решение:
В случае непрерывного признака целесообразно строить гистограмму, для чего интервал, в котором заключены все наблюдаемые значения признака, разбивают на несколько частичных интервалов длиной h и находят для кажд ого частичного интервала n i – сумму частот вариант, попавших в i -ый интервал. (Например, при измерении роста человека или веса, мы имеем дело с непрерывным признаком).
Гистограмма частот- это ступенчатая фигура, состоящая из прямоугольников, основаниями которых служат частичные интервалы длиною h , а высоты равны отношению (плотность частот).
Площадь i -го частичного прямоугольника равна- сумме частот вариант i - го интервала, т.е. площадь гистограммы частот равна сумме всех частот, т.е. объему выборки.
Пример:
Даны результаты изменения напряжения (в вольтах) в электросети. Составьте вариационный ряд, постройте полигон и гистограмму частот, если значения напряжения следующие: 227, 215, 230, 232, 223, 220, 228, 222, 221, 226, 226, 215, 218, 220, 216, 220, 225, 212, 217, 220.
Решение:
Составим вариационный ряд. Имеем n = 20, x min =212, x max =232 .
Применим формулу Стреджесса для подсчета числа интервалов.
Интервальный вариационный ряд частот имеет вид:
|
|
Плотность частот |
|
212-21 6 |
0,75 |
|
|
21 6-22 0 |
0,75 |
|
|
220-224 |
1,75 |
|
|
224-228 |
||
|
228-232 |
0,75 |
Построим гистограмму частот:
Построим полигон частот, найдя предварительно середины интервалов:
Гистограммой относительных частот называют ступенчатую фигуру, состоящую из прямоугольников, основаниями которыхслужат частичные интервалы длиною h , а высоты равны отношению w i /h (плотность относительной частоты).
Площадь i -го частичного прямоугольника равна- относительной частоте вариант, попавших в i - ый интервал. Т.е. площадь гистограммы относительных частот равна сумме всех относительных частот, т.е. единице.
7. Числовые характеристики вариационного ряда
Рассмотрим основные характеристики генеральной и выборочной совокупностей.
Генеральным средним называется среднее арифметическое значений признака генеральной совокупности.
Для различных значений x 1 , x 2 , x 3 , …, x n . признака генеральной совокупности объема N имеем:
Если значения признака имеют соответствующие частоты N 1 +N 2 +…+N k =N , то
Выборочным средним называется среднее арифметическое значений признака выборочной совокупности.
Если значения признака имеют соответствующие частоты n 1 +n 2 +…+n k = n , то
Пример:
Вычислите выборочное среднее для выборки: x 1 = 51,12; x 2 = 51,07;x 3 = 52,95; x 4 =52,93;x 5 = 51,1;x 6 = 52,98; x 7 = 52,29; x 8 = 51,23; x 9 = 51,07; x 10 = 51,04.
Решение:
Генеральной дисперсией называется среднее арифметическое квадратов отклонений значений признака Х генеральной совокупности от генерального среднего.
Для различных значений x 1 , x 2 , x 3 , …, x N признака генеральной совокупности объема N имеем:
Если значения признака имеют соответствующие частоты N 1 +N 2 +…+N k =N , то
Генеральным среднеквадратическим отклонением (стандартом) называют квадратный корень из генеральной дисперсии
Выборочной дисперсией называется среднее арифметическое квадратов отклонений наблюдаемых значений признака от среднего значения.
Для различных значений x 1 , x 2 , x 3 , …, x n признака выборочной совокупности объема n имеем:
Если значения признака имеют соответствующие частоты n 1 +n 2 +…+n k = n , то
Выборочным среднеквадратическим отклонением (стандартом) называется квадратный корень из выборочной дисперсии.
Пример:
Выборочная совокупность задана таблицей распределения. Найдите выборочную дисперсию.
Решение:
Теорема: Дисперсия равна разности среднего квадратов значений признака и квадрата общего среднего.
Пример:
Найдите дисперсию по данному распределению.
Решение:
8. Статистические оценки параметров распределения
Пусть генеральная совокупность исследуется по некоторой выборке. При этом можно получить лишь приближенное значение неизвестного параметра Q , который служит его оценкой. Очевидно, что оценки могут изменяться от одной выборки к другой.
Статистической оценкой Q * неизвестного параметра теоретического распределения называется функция f , зависящая от наблюдаемых значений выборки. Задачей статистического оценивания неизвестных параметров по выборке заключается в построении такой функции от имеющихся данных статистических наблюдений, которая давала бы наиболее точные приближенные значения реальных, не известных исследователю, значений этих параметров.
Статистические оценки делятся на точечные и интервальные, в зависимости от способа их предоставления (числом или интервалом).
Точечной называют статистическую оценку параметра Q теоретического распределения определяемую одним значением параметра Q *=f (x 1 , x 2 , ..., x n), где x 1 , x 2 , ..., x n - результаты эмпирических наблюдений над количественным признаком Х некоторой выборки.
Такие оценки параметров, полученные по разным выборкам, чаще всего отличаются друг от друга. Абсолютная разность /Q *-Q / называют ошибкой выборки (оценивания).
Для того, чтобы статистические оценки давали достоверные результаты об оцениваемых параметрах, необходимо, чтобы они были несмещенными, эффективными и состоятельными.
Точечная оценка , математическое ожидание которой равно (не равно) оцениваемому параметру, называется несмещенной (смещенной) . М(Q *)=Q .
Разность М(Q *)-Q называют смещением или систематической ошибкой . Для несмещенных оценок систематическая ошибка равна 0.
Эффективной оценку Q *, которая при заданном объеме выборки n имеет наименьшую возможную дисперсию: D min (n = const ). Эффективная оценка имеет наименьший разброс по сравнению с другими несмещенными и состоятельными оценками.
Состоятельной называют такую статистическую оценку Q *, которая при n стремится по вероятности к оцениваемому параметру Q , т.е. при увеличении объема выборки n оценка стремится по вероятности к истинному значению параметра Q .
Требование состоятельности согласуется с законом больших числе: чем больше исходной информации об исследуемом объекте, тем точнее результат. Если объем выборки мал, то точечная оценка параметра может привести к серьезным ошибкам.
Любую выборку (объема n ) можно рассматривать как упорядоченный набор x 1 , x 2 , ..., x n независимых одинаково распределенных случайных величин.
Выборочные средние для различных выборок объема n из одной и той же генеральной совокупности будут различны. Т. е. выборочное среднее можно рассматривать как случайную величину, а значит, можно говорить о распределении выборочного среднего и его числовых характеристиках.
Выборочное среднее удовлетворяет всем накладываемым к статистическим оценкам требованиям, т.е. дает несмещенную, эффективную и состоятельную оценку генерального среднего.
Можно доказать, что . Таким образом, выборочная дисперсия является смещенной оценкой генеральной дисперсии, давая ее заниженное значение. Т. е. при небольшом объеме выборки она будет давать систематическую ошибку. Для несмещенной, состоятельной оценки достаточно взять величину , которую называют исправленной дисперсией. Т. е.
На практике для оценки генеральной дисперсии применяют исправленную дисперсию при n < 30. В остальных случаях (n >30) отклонение от малозаметно. Поэтому при больших значениях n ошибкой смещения можно пренебречь.
Можно так же доказать,что относительная частота n i / n является несмещенной и состоятельной оценкой вероятности P (X =x i ). Эмпирическая функция распределения F *(x ) является несмещенной и состоятельной оценкой теоретической функции распределения F (x )= P (X < x ).
Пример:
Найдите несмещенные оценки математического ожиданияи дисперсии по таблице выборки.
|
x i |
|||
|
n i |
Решение:
Объем выборки n =20.
Несмещенной оценкой математического ожидания является выборочное среднее.
Для вычисления несмещенной оценки дисперсии сначала найдем выборочную дисперсию:
Теперь найдем несмещенную оценку:
9. Интервальные оценки параметров распределения
Интервальной называется статистическая
оценка, определяемая двумя числовыми значениями- концами исследуемого
интервала.
Число > 0, при котором | Q - Q *|< , характеризует точность интервальной оценки.
Доверительным называется интервал , который с заданной вероятностью покрывает неизвестное значение параметра Q . Дополнение доверительного интервала до множества всех возможных значений параметра Q называется критической областью . Если критическая область расположена только с одной стороны от доверительного интервала, то доверительный интервал называется односторонним: левосторонним , если критическая область существует только слева, и правосторонним- если только справа. В противном случае, доверительный интервал называется двусторонним .
Надежностью, или доверительной вероятностью, оценки Q (с помощью Q *) называют вероятность, с которой выполняется следующее неравенство: | Q - Q *|< .
Чаще всего доверительную вероятность задают заранее (0,95; 0,99; 0,999) и на нее накладывают требование быть близкой к единице.
Вероятность называют вероятностью ошибки, или уровнем значимости.
Пусть | Q - Q *|< , тогда . Это означает, что с вероятностью можно утверждать, что истинное значение параметра Q принадлежит интервалу . Чем меньше величина отклонения , тем точнее оценка.
Границы (концы) доверительного интервала называют доверительными границами, или критическими границами.
Значения границ доверительного интервала зависят от закона распределения параметра Q *.
Величину отклонения равную половине ширины доверительного интервала, называют точностью оценки.
Методы построения доверительных интервалов впервые были разработаны американским статистом Ю. Нейманом. Точность оценки , доверительная вероятность и объем выборки n связаны между собой. Поэтому, зная конкретные значения двух величин, всегда можно вычислить третью.
Нахождение доверительного интервала для оценки математического ожидания нормального распределения, если известно среднеквадратическое отклонение.
Пусть произведена выборка из генеральной совокупности, подчиненной закону нормального распределения. Пусть известно генеральное среднеквадратическое отклонение , но неизвестно математическое ожидание теоретического распределения a ( ).
Справедлива следующая формула:
Т.е. по заданному значению отклонения можно найти, с какой вероятностью неизвестное генеральное среднее принадлежит интервалу . И наоборот. Из формулы видно, что при возрастании объема выборки и фиксированной величине доверительной вероятности величина - уменьшается, т.е. точность оценки увеличивается. С увеличением надежности (доверительной вероятности), величина -увеличивается, т.е. точность оценки уменьшается.
Пример:
В результате испытаний были получены следующие значения -25, 34, -20, 10, 21. Известно, что они подчиняются закону нормального распределения с среднеквадратическим отклонением 2. Найдите оценку а* для математического ожидания а. Постройте для него 90%-ый доверительный интервал.
Решение:
Найдем несмещенную оценку
Тогда
Доверительный интервал для а имеет вид: 4 – 1,47< a < 4+ 1,47 или 2,53 < a < 5, 47
Нахождение доверительного интервала для оценки математического ожидания нормального распределения, если неизвестно среднеквадратическое отклонение.
Пусть известно, что генеральная совокупность подчинена закону нормального распределения, где неизвестны а и . Точность доверительного интервала, покрывающего с надежностью истинное значение параметра а, в данном случае вычисляется по формуле:
, где n - объем выборки, , - коэффициент Стьюдента (его следует находить по заданным значениям n и из таблицы «Критические точки распределения Стьюдента»).
Пример:
В результате испытаний были получены следующие значения -35, -32, -26, -35, -30, -17. Известно, что они подчиняются закону нормального распределения. Найдите доверительный интервал для математического ожидания а генеральной совокупности с доверительной вероятностью 0,9.
Решение:
Найдем несмещенную оценку .
Найдем .
Тогда
Доверительный интервал примет вида (-29,2 - 5,62; -29,2 + 5,62) или (-34,82; -23,58).
Нахождение доверительного интерла для дисперсии и среднеквадратического отклонения нормального распределения
Пусть из некоторой генеральной совокупности значений, распределенной по нормальному закону, взята случайная выборка объема n < 30, для которой вычислены выборочные дисперсии: смещенная и исправленная s 2 . Тогда для нахождения интервальных оценок с заданной надежностью для генеральной дисперсии D генерального среднеквадратического отклонения используются следующие формулы.
или ,
Значения - находят с помощью таблицы значений критических точек распределения Пирсона.
Доверительный интервал для дисперсии находится из этих неравенств путем возведения всех частей неравенства в квадрат.
Пример:
Было проверено качество 15 болтов. Предполагая, что ошибка при их изготовлении подчинена нормальному закону распределения, причем выборочное среднеквадратическое отклонение равно 5 мм, определить с надежностью доверительный интервал для неизвестного параметра
Границы интервала представим в виде двойного неравенства:
Концы двустороннего доверительного интервала для дисперсии можно определить и без выполнения арифметических действий по заданному уровню доверия и объему выборки с помощью соответствующей таблицы (Границы доверительных интервалов для дисперсии в зависимости от числа степеней свободы и надежности). Для этого полученные из таблицы концы интервала умножают на исправленную дисперсию s 2 .
Пример:
Решим предыдущую задачу другим способом.
Решение:
Найдем исправленную дисперсию:
По таблице «Границы доверительных интервалов для дисперсии в зависимости от числа степеней свободы и надежности» найдем границы доверительного интервала для дисперсии при k =14 и : нижняя граница 0,513 и верхняя 2,354.
Умножим полученные границы на s 2 и извлечем корень (т.к. нам нужен доверительный интервал не для дисперсии, а для среднеквадратического отклонения).
Как видно из примеров, величина доверительного интервала зависит от способа его построения и дает близкие между собой, но неодинаковые результаты.
При выборках достаточно большого объема (n >30) границы доверительного интервала для генерального среднеквадратического отклонения можно определить по формуле: - некоторое число, которое табулировано и приводится в соответствующей справочной таблице.
Если 1- q <1, то формула имеет вид:
Пример:
Решим предыдущую задачу третьим способом.
Решение:
Ранее было найдено s = 5,17. q (0,95; 15) = 0,46 – находим по таблице.
Тогда:
Выбор редакции
-
 Взять ружье и пойти в лес охотиться на дичь – хорошо ведь! Тишина, листья шумят, только ты да верный пес. А тут...
Взять ружье и пойти в лес охотиться на дичь – хорошо ведь! Тишина, листья шумят, только ты да верный пес. А тут... -
 Мы с вами уже разобрали все важные моменты в теории и практике написания синквейнов, а сегодня я представлю примеры...
Мы с вами уже разобрали все важные моменты в теории и практике написания синквейнов, а сегодня я представлю примеры... -
 Методика "двух стульев" была разработана в рамках гештальттерапии, в которой в настоящее время в основном и...
Методика "двух стульев" была разработана в рамках гештальттерапии, в которой в настоящее время в основном и... -
 Последнее обновление 07.10.2019 Московские семьи - самые привилегированные в плане поддержки от государства. В...
Последнее обновление 07.10.2019 Московские семьи - самые привилегированные в плане поддержки от государства. В... -
 Оформить может не только мать, но и отец (либо опекуны). Стоит учитывать, что право на получение пособия возникает...
Оформить может не только мать, но и отец (либо опекуны). Стоит учитывать, что право на получение пособия возникает... -
 В ст. 78 УК установлено, что в качестве одного из оснований для освобождения от ответственности выступает истечение...
В ст. 78 УК установлено, что в качестве одного из оснований для освобождения от ответственности выступает истечение... -
 Как известно, в своей деятельности, многие предприниматели сталкиваются с противодействием со стороны...
Как известно, в своей деятельности, многие предприниматели сталкиваются с противодействием со стороны... -
 В советские времена зарубежное технологическое оборудование закупалось исключительно отраслевыми министерствами....
В советские времена зарубежное технологическое оборудование закупалось исключительно отраслевыми министерствами.... -
 Доверенность от ИП выдается в тех случаях, когда представлять интересы индивидуального предпринимателя в...
Доверенность от ИП выдается в тех случаях, когда представлять интересы индивидуального предпринимателя в... -
 - «В СМИ сообщают, что на президентских выборах 2018 года будет действовать новый порядок включения граждан в...
- «В СМИ сообщают, что на президентских выборах 2018 года будет действовать новый порядок включения граждан в...