Алгоритм распространения ошибки обратно по времени. Метод обратного распространения ошибки: математика, примеры, код
В многослойных нейронных сетях оптимальные выходные значения нейронов всех слоев, кроме последнего, как правило, неизвестны трех- или более слойный персептрон уже невозможно обучить, руководствуясь только величинами ошибок на выходах сети
Один из вариантов решения этой проблемы - разработка наборов выходных сигналов, соответствующих входным, для каждого слоя нейронной сети, что, конечно, является очень трудоемкой операцией и не всегда осуществимо Второй вариант - динамическая подстройка весовых коэффициентов синапсов, в ходе которой выбираются, как правило, наиболее слабые связи и изменяются на малую величину в ту или иную сторону, а сохраняются только те изменения, которые повлекли уменьшение ошибки на выходе всей сети Очевидно, что данный метод, несмотря на
кажущуюся простоту, требует громоздких рутинных вычислений И, наконец, третий, более приемлемый вариант - распространение сигналов ошибки от выходов нейронной сети к ее входам, в направлении, обратном прямому распространению сигналов в обычном режиме работы Этот алгоритм обучения получил название процедуры обратного распространения ошибки (error back propagation) Именно он рассматривается ниже
Алгоритм обратного распространения ошибки - это итеративный градиентный алгоритм обучения, который используется с целью минимизации среднеквадратичного отклонения текущих от требуемых выходов многослойных нейронных сетей с последовательными связями
Согласно методу наименьших квадратов, минимизируемой целевой функцией ошибки нейронной сети является величина
где - реальное выходное состояние нейрона у выходного слоя нейронной сети при подаче на ее входы образа, требуемое выходное состояние этого нейрона
Суммирование ведется по всем нейронам выходного слоя и по всем обрабатываемым сетью образам Минимизация методом градиентного спуска обеспечивает подстройку весовых коэффициентов следующим образом
![]()
где - весовой коэффициент синаптической связи, соединяющей нейрон слоя нейроном слоя - коэффициент скорости обучения,
В соответствии с правилом дифференцирования сложной функции

где - взвешенная сумма входных сигналов нейрона аргумент активационной функции Так как производная активационной функции должна быть определена на всей оси абсцисс, то функция единичного скачка и прочие активационные функции с неоднородностями не подходят для рассматриваемых нейронных сетей В них применяются такие гладкие функции, как гиперболический тангенс или классический сигмоид с экспонентой (см табл 1 1) Например, в случае гиперболического тангенса
Третий множитель равен выходу нейрона предыдущего слоя
Что касается первого множителя в (1.11), он легко раскладывается следующим образом:
Здесь суммирование по выполняется среди нейронов слоя Введя новую переменную:
![]()
получим рекурсивную формулу для расчетов величин слоя из величин более старшего слоя
![]()
Для выходного слоя:

Теперь можно записать (1.10) в раскрытом виде:
![]()
Иногда для придания процессу коррекции весов некоторой инерционности, сглаживающей резкие скачки при перемещении по поверхности целевой функции, (1.17) дополняется значением изменения веса на предыдущей итерации.
где коэффициент инерционности; номер текущей итерации.
Таким образом, полный алгоритм обучения нейронной сети с помощью процедуры обратного распространения строится следующим образом.
ШАГ 1. Подать на входы сети один из возможных образов и в режиме обычного функционирования нейронной сети, когда сигналы распространяются от входов к выходам, рассчитать значения последних. Напомним, что:
![]()
где - число нейронов в слое с учетом нейрона с постоянным выходным состоянием задающего смещение; вход нейрона у слоя
где - сигмоид,
где компонента вектора входного образа.
ШАГ 4. Скорректировать все веса в нейронной сети:
ШАГ 5. Если ошибка сети существенна, перейти на шаг 1. В противном случае - конец.
Сети на шаге 1 попеременно в случайном порядке предъявляются все тренировочные образы, чтобы сеть, образно говоря, не забывала одни по мере запоминания других.
Из выражения (1.17) следует, что когда выходное значение стремится к нулю, эффективность обучения заметно снижается. При двоичных входных векторах в среднем половина весовых коэффициентов не будет корректироваться, поэтому область возможных значений выходов нейронов желательно сдвинуть в пределы что достигается простыми модификациями логистических функций. Например, сигмоид с экспонентой преобразуется к виду:
![]()
Рассмотрим вопрос о емкости нейронной сети, т. е. числа образов, предъявляемых на ее входы, которые она способна научиться распознавать. Для сетей с числом слоев больше двух, этот вопрос остается открытым. Для сетей с двумя слоями, детерминистская емкость сети оценивается следующим образом:
![]()
где - число подстраиваемых весов, - число нейронов в выходном слое.
Данное выражение получено с учетом некоторых ограничений. Во-первых, число входов и нейронов в скрытом слое должно удовлетворять неравенству Во-вторых, Однако приведенная оценка выполнена для сетей с пороговыми активационными функциями нейронов, а емкость сетей с гладкими активационными функциями, например (1.23), обычно больше. Кроме того, термин детерминистский означает, что полученная оценка емкости подходит для всех входных образов, которые могут быть представлены входами. В действительности распределение входных образов, как правило, обладает некоторой регулярностью, что позволяет нейронной сети проводить обобщение и, таким образом, увеличивать реальную емкость. Так как распределение образов, в общем случае, заранее не известно, можно говорить о реальной емкости только предположительно, но обычно она раза в два превышает детерминистскую емкость.
Вопрос о емкости нейронной сети тесно связан с вопросом о требуемой мощности выходного слоя сети, выполняющего окончательную классификацию образов. Например, для разделения множества входных образов по двум классам достаточно одного выходного нейрона. При этом каждый логический уровень будет обозначать отдельный класс. На двух выходных нейронах с пороговой функцией активации можно закодировать уже четыре класса. Для повышения достоверности классификации желательно ввести избыточность путем выделения каждому классу одного нейрона в выходном слое или, что еще лучше, нескольких, каждый из которых обучается определять принадлежность образа к классу со своей степенью достоверности, например: высокой, средней и низкой. Такие нейронные сети позволяют проводить классификацию входных образов, объединенных в нечеткие (размытые или пересекающиеся) множества. Это свойство приближает подобные сети к реальным условиям функционирования биологических нейронных сетей.
Рассматриваемая нейронная сеть имеет несколько «узких мест». Во-первых, в процессе большие положительные или отрицательные значения весов могут сместить рабочую точку на сигмоидах нейронов в область насыщения. Малые величины производной от логистической функции приведут в соответствии с (1.15) и (1.16) к остановке обучения, что парализует сеть. Во-вторых, применение метода градиентного спуска не гарантирует нахождения глобального минимума целевой функции. Это тесно связано вопросом выбора скорости обучения. Приращения весов и, следовательно, скорость обучения для нахождения экстремума должны быть бесконечно малыми, однако в этом случае обучение будет
происходить неприемлемо медленно. С другой стороны, слишком большие коррекции весов могут привести к постоянной неустойчивости процесса обучения. Поэтому в качестве коэффициента скорости обучения 1] обычно выбирается число меньше 1 (например, 0,1), которое постепенно уменьшается в процессе обучения. Кроме того, для исключения случайных попаданий сети в локальные минимумы иногда, после стабилизации значений весовых коэффициентов, 7 кратковременно значительно увеличивают, чтобы начать градиентный спуск из новой точки. Если повторение этой процедуры несколько раз приведет сеть в одно и то же состояние, можно предположить, что найден глобальный минимум.
Существует другой метод исключения локальных минимумов и паралича сети, заключающийся в применении стохастических нейронных сетей.
Дадим изложенному геометрическую интерпретацию.
В алгоритме обратного распространения вычисляется вектор градиента поверхности ошибок. Этот вектор указывает направление кратчайшего спуска по поверхности из текущей точки, движение по которому приводит к уменьшению ошибки. Последовательность уменьшающихся шагов приведет к минимуму того или иного типа. Трудность здесь представляет вопрос подбора длины шагов.
При большой величине шага сходимость будет более быстрой, но имеется опасность перепрыгнуть через решение или в случае сложной формы поверхности ошибок уйти в неправильном направлении, например, продвигаясь по узкому оврагу с крутыми склонами, прыгая с одной его стороны на другую. Напротив, при небольшом шаге и верном направлении потребуется очень много итераций. На практике величина шага берется пропорциональной крутизне склона, так что алгоритм замедляет ход вблизи минимума. Правильный выбор скорости обучения зависит от конкретной задачи и обычно делается опытным путем. Эта константа может также зависеть от времени, уменьшаясь по мере продвижения алгоритма.
Обычно этот алгоритм видоизменяется таким образом, чтобы включать слагаемое импульса (или инерции). Это способствует продвижению в фиксированном направлении, поэтому, если было сделано несколько шагов в одном и том же направлении, то алгоритм увеличивает скорость, что иногда позволяет избежать локального минимума, а также быстрее проходить плоские участки.
На каждом шаге алгоритма на вход сети поочередно подаются все обучающие примеры, реальные выходные значения сети сравниваются с требуемыми значениями, и вычисляется ошибка. Значение ошибки, а также градиента поверхности ошибок
используется для корректировки весов, после чего все действия повторяются. Процесс обучения прекращается либо когда пройдено определенное количество эпох, либо когда ошибка достигнет некоторого определенного малого уровня, либо когда ошибка перестанет уменьшаться.
Рассмотрим проблемы обобщения и переобучения нейронной сети более подробно. Обобщение - это способность нейронной сети делать точный прогноз на данных, не принадлежащих исходному обучающему множеству. Переобучение же представляет собой чрезмерно точную подгонку, которая имеет место, если алгоритм обучения работает слишком долго, а сеть слишком сложна для такой задачи или для имеющегося объема данных.
Продемонстрируем проблемы обобщения и переобучения на примере аппроксимации некоторой зависимости не нейронной сетью, а посредством полиномов, при этом суть явления будет абсолютно та же.
Графики полиномов могут иметь различную форму, причем, чем выше степень и число членов, тем более сложной может быть эта форма. Для исходных данных можно подобрать полиномиальную кривую (модель) и получить, таким образом, объяснение имеющейся зависимости. Данные могут быть зашумлены, поэтому нельзя считать, что лучшая модель в точности проходит через все имеющиеся точки. Полином низкого порядка может лучше объяснять имеющуюся зависимость, однако, быть недостаточно гибким средством для аппроксимации данных, в то время как полином высокого порядка может оказаться чересчур гибким, но будет точно следовать данным, принимая при этом замысловатую форму, не имеющую никакого отношения к настоящей зависимости.
Нейронные сети сталкивается с такими же трудностями. Сети с большим числом весов моделируют более сложные функции и, следовательно, склонны к переобучению. Сети же с небольшим числом весов могут оказаться недостаточно гибкими, чтобы смоделировать имеющиеся зависимости. Например, сеть без скрытых слоев моделирует лишь обычную линейную функцию.
Как же выбрать правильную степень сложности сети? Почти всегда более сложная сеть дает меньшую ошибку, но это может свидетельствовать не о хорошем качестве модели, а о переобучении сети.
Выход состоит в использовании контрольной кросс-проверки. Для этого резервируется часть обучающей выборки, которая используется не для обучения сети по алгоритму обратного распространения ошибки, а для независимого контроля результата в ходе алгоритма. В начале работы ошибка сети на обучающем и
контрольном множествах будет одинаковой. По мере обучения сети ошибка обучения убывает, как и ошибка на контрольном множестве. Если же контрольная ошибка перестала убывать или даже стала расти, это указывает на то, что сеть начала слишком близко аппроксимировать данные (переобучилась) и обучение следует остановить. Если это случилось, то следует уменьшить число скрытых элементов и/или слоев, ибо сеть является слишком мощной для данной задачи. Если же обе ошибки (обучения и кросспроверки) не достигнут достаточного малого уровня, то переобучения, естественно не произошло, а сеть, напротив, является недостаточно мощной для моделирования имеющейся зависимости.
Описанные проблемы приводят к тому, что при практической работе с нейронными сетями приходится экспериментировать с большим числом различных сетей, порой обучая каждую из них по несколько раз и сравнивая полученные результаты. Главным показателем качества результата является здесь контрольная ошибка. При этом, в соответствии с общесистемным принципом, из двух сетей с приблизительно равными ошибками контроля имеет смысл выбрать ту, которая проще.
Необходимость многократных экспериментов приводит к тому, что контрольное множество начинает играть ключевую роль в выборе модели и становится частью процесса обучен-ия. Тем самым ослабляется его роль как независимого критерия качества модели. При большом числе экспериментов есть большая вероятность выбрать удачную сеть, дающую хороший результат на контрольном множестве. Однако для того чтобы придать окончательной модели должную надежность, часто (когда объем обучающих примеров это позволяет) поступают следующим образом: резервируют тестовое множество примеров. Итоговая модель тестируется на данных из этого множества, чтобы убедиться, что результаты, достигнутые на обучающем и контрольном множествах примеров, реальны, а не являются артефактами процесса обучения. Разумеется, для того чтобы хорошо играть свою роль, тестовое множество должно быть использовано только один раз: если его использовать повторно для корректировки процесса обучения, то оно фактически превратится в контрольное множество.
С целью ускорения процесса обучения сети предложены многочисленные модификации алгоритма обратного распространения ошибки, связанные с использованием различных функций ошибки, процедур определения направления и величин шага.
1) Функции ошибки:
Интегральные функции ошибки по всей совокупности обучающих примеров;
Функции ошибки целых и дробных степеней
2) Процедуры определения величины шага на каждой итерации
Дихотомия;
Инерционные соотношения (см выше);
3) Процедуры определения направления шага.
С использованием матрицы производных второго порядка (метод Ньютона);
С использованием направлений на нескольких шагах (партан метод).
Прудников Иван Алексеевич
МИРЭА(МТУ)
Тема нейронных сетей была уже ни раз освещена во многих журналах, однако сегодня я бы хотел познакомить читателей с алгоритмом обучения многослойной нейронной сети методом обратного распространения ошибки и привести реализацию данного метода.
Сразу хочу оговориться, что не являюсь экспертом в области нейронных сетей, поэтому жду от читателей конструктивной критики, замечаний и дополнений.
Теоретическая часть
Данный материал предполагает знакомство с основами нейронных сетей, однако я считаю возможным ввести читателя в курс темы без излишних мытарств по теории нейронных сетей. Итак, для тех, кто впервые слышит словосочетание «нейронная сеть», предлагаю воспринимать нейронную сеть в качестве взвешенного направленного графа, узлы (нейроны) которого расположены слоями. Кроме того, узел одного слоя имеет связи со всеми узлами предыдущего слоя. В нашем случае у такого графа будут иметься входной и выходной слои, узлы которых выполняют роль входов и выходов соответственно. Каждый узел (нейрон) обладает активационной функцией - функцией, ответственной за вычисление сигнала на выходе узла (нейрона). Также существует понятие смещения, представляющего из себя узел, на выходе которого всегда появляется единица. В данной статье мы будем рассматривать процесс обучения нейронной сети, предполагающий наличие «учителя», то есть процесс обучения, при котором обучение происходит путем предоставления сети последовательности обучающих примеров с правильными откликами.
Как и в случае с большинством нейронных сетей, наша цель состоит в обучении сети таким образом, чтобы достичь баланса между способностью сети давать верный отклик на входные данные, использовавшиеся в процессе обучения (запоминания), и способностью выдавать правильные результаты в ответ на входные данные, схожие, но неидентичные тем, что были использованы при обучении (принцип обобщения). Обучение сети методом обратного распространения ошибки включает в себя три этапа: подачу на вход данных, с последующим распространением данных в направлении выходов, вычисление и обратное распространение соответствующей ошибки и корректировку весов. После обучения предполагается лишь подача на вход сети данных и распространение их в направлении выходов. При этом, если обучение сети может являться довольно длительным процессом, то непосредственное вычисление результатов обученной сетью происходит очень быстро. Кроме того, существуют многочисленные вариации метода обратного распространения ошибки, разработанные с целью увеличения скорости протекания процесса обучения.
Также стоит отметить, что однослойная нейронная сеть существенно ограничена в том, обучению каким шаблонам входных данных она подлежит, в то время, как многослойная сеть (с одним или более скрытым слоем) не имеет такого недостатка. Далее будет дано описание стандартной нейронной сети с обратным распространением ошибки.
Архитектура
На рисунке 1 показана многослойная нейронная сеть с одним слоем скрытых нейронов (элементы Z).
Нейроны, представляющие собой выходы сети (обозначены Y), и скрытые нейроны могут иметь смещение(как показано на изображении). Смещение, соответствующий выходу Y k обозначен w ok , скрытому элементу Z j - V oj . Эти смещения служат в качестве весов на связях, исходящих от нейронов, на выходе которых всегда появляется 1 (на рисунке 1 они показаны, но обычно явно не отображаются, подразумеваясь). Кроме того, на рисунке 1 стрелками показано перемещение информации в ходе фазы распространения данных от входов к выходам. В процессе обучения сигналы распространяются в обратном направлении.
Описание алгоритма
Алгоритм, представленный далее, применим к нейронной сети с одним скрытым слоем, что является допустимой и адекватной ситуацией для большинства приложений. Как уже было сказано ранее, обучение сети включает в себя три стадии: подача на входы сети обучающих данных, обратное распространение ошибки и корректировка весов. В ходе первого этапа каждый входной нейрон X i получает сигнал и широковещательно транслирует его каждому из скрытых нейронов Z 1 ,Z 2 ...,Z p . Каждый скрытый нейрон затем вычисляет результат его активационной функции (сетевой функции) и рассылает свой сигнал Z j всем выходным нейронам. Каждый выходной нейрон Y k , в свою очередь, вычисляет результат своей активационной функции Y k , который представляет собой ничто иное, как выходной сигнал данного нейрона для соответствующих входных данных. В процессе обучения, каждый нейрон на выходе сети сравнивает вычисленное значение Y k с предоставленным учителем t k (целевым значением), определяя соответствующее значение ошибки для данного входного шаблона. На основании этой ошибки вычисляется σ k (k = 1,2,...m). σ k используется при распространении ошибки от Y k до всех элементов сети предыдущего слоя (скрытых нейронов, связанных с Y k), а также позже при изменении весов связей между выходными нейронами и скрытыми. Аналогичным образом вычисляется σj
(j = 1,2,...p) для каждого скрытого нейрона Z j . Несмотря на то, что распространять ошибку до входного слоя необходимости нет, σj используется для изменения весов связей между нейронами скрытого слоя и входными нейронами. После того как все σ были определены, происходит одновременная корректировка весов всех связей.
Обозначения:
В алгоритме обучения сети используются следующие обозначения:
X Входной вектор обучающих данных X = (X 1 , X 2 ,...,X i ,...,X n).
t Вектор целевых выходных значений, предоставляемых учителем t = (t 1 , t 2 ,...,t k ,...,t m)
σ k Составляющая корректировки весов связей w jk , соответствующая ошибке выходного нейрона Y k ; также, информация об ошибке нейрона Y k , которая распространяется тем нейронам скрытого слоя, которые связаны с Y k .
σ j Составляющая корректировки весов связей v ij , соответствующая распространяемой от выходного слоя к скрытому нейрону Z j информации об ошибке.
a Скорость обучения.
X i Нейрон на входе с индексом i. Для входных нейронов входной и выходной сигналы одинаковы - X i .
v oj Смещение скрытого нейрона j.
Z j Скрытый нейрон j; Суммарное значение подаваемое на вход скрытого элемента Z j обозначается Z_in j: Z_in j = v oj +∑x i *v ij
Сигнал на выходе Z j (результат применения к Z_in j активационной функции) обозначается Z j: Z j = f (Z_in j)
w ok Смещение нейрона на выходе.
Y k Нейрон на выходе под индексом k; Суммарное значение подаваемое на вход выходного элемента Y k обозначается Y_in k: Y_in k = w ok + ∑ Z j *w jk . Сигнал на выходе Y k (результат применения к Y_in k активационной функции) обозначается Y k:
Функция активации
Функция активация в алгоритме обратного распространения ошибки должна обладать несколькими важными характеристиками: непрерывностью, дифференцируемостью и являться монотонно неубывающей. Более того, ради эффективности вычислений, желательно, чтобы ее производная легко находилась. Зачастую, активационная функция также является функцией с насыщением. Одной из наиболее часто используемых активационных функций является бинарная сигмоидальная функция с областью значений в (0, 1) и определенная как:

Другой широко распространенной активационной функцией является биполярный сигмоид с областью значений (-1, 1) и определенный как:

Алгоритм обучения
Алгоритм обучения выглядит следующим образом:
Инициализация весов (веса всех связей инициализируются случайными небольшими значениями).
До тех пор пока условие прекращения работы алгоритма неверно, выполняются шаги 2 - 9.
Для каждой пары { данные, целевое значение } выполняются шаги 3 - 8.
Распространение данных от входов к выходам:
Шаг 3.
Каждый входной нейрон (X i , i = 1,2,...,n) отправляет полученный сигнал X i всем нейронам в следующем слое (скрытом).
Каждый скрытый нейрон (Z j , j = 1,2,...,p) суммирует взвешенные входящие сигналы: z_in j = v oj + ∑ x i *v ij и применяет активационную функцию: z j = f (z_in j) После чего посылает результат всем элементам следующего слоя (выходного).
Каждый выходной нейрон (Y k , k = 1,2,...m) суммирует взвешенные входящие сигналы: Y_in k = w ok + ∑ Z j *w jk и применяет активационную функцию, вычисляя выходной сигнал: Y k = f (Y_in k).
Обратное распространение ошибки:
Каждый выходной нейрон (Y k , k = 1,2,...m) получает целевое значение - то выходное значение, которое является правильным для данного входного сигнала, и вычисляет ошибку: σ k = (t k - y k)*f " (y_in k), так же вычисляет величину, на которую изменится вес связи w jk: Δw jk = a * σ k * z j . Помимо этого, вычисляет величину корректировки смещения: Δw ok = a*σ k и посылает σ k нейронам в предыдущем слое.
Каждый скрытый нейрон (z j , j = 1,2,...p) суммирует входящие ошибки (от нейронов в последующем слое) σ_in j = ∑ σ k * w jk и вычисляет величину ошибки, умножая полученное значение на производную активационной функции: σ j = σ_in j * f " (z_in j), так же вычисляет величину, на которую изменится вес связи vij: Δv ij = a * σ j * x i . Помимо этого, вычисляет величину корректировки смещения: v oj = a * σ j
Шаг 8. Изменение весов.
Каждый выходной нейрон (y k , k = 1,2,...,m) изменяет веса своих связей с элементом смещения и скрытыми нейронами: w jk (new) = w jk (old) + Δw jk
Каждый скрытый нейрон (z j , j = 1,2,...p) изменяет веса своих связей с элементом смещения и выходными нейронами: v ij (new) = v ij (old) + Δv ij
Проверка условия прекращения работы алгоритма.
Условием прекращения работы алгоритма может быть как достижение суммарной квадратичной ошибкой результата на выходе сети предустановленного заранее минимума в ходе процесса обучения, так и выполнения определенного количества итераций алгоритма. В основе алгоритма лежит метод под названием градиентный спуск. В зависимости от знака, градиент функции (в данном случае значение функции - это ошибка, а параметры - это веса связей в сети) дает направление, в котором значения функции возрастают (или убывают) наиболее стремительно.
В предыдущей части мы учились рассчитывать изменения сигнала при проходе по нейросети. Мы познакомились с матрицами, их произведением и вывели простые формулы для расчетов.
В 6 части перевода выкладываю сразу 4 раздела книги. Все они посвящены одной из самых важных тем в области нейросетей - методу обратного распространения ошибки. Вы научитесь рассчитывать погрешность всех нейронов нейросети основываясь только на итоговой погрешности сети и весах связей.
Материал сложный, так что смело задавайте свои вопросы на форуме.
Вы можете перевода.
Приятного чтения!
1 Глава. Как они работают.
1.10 Калибровка весов нескольких связей
Ранее мы настраивали линейный классификатор с помощью изменения постоянного коэффициента уравнения прямой. Мы использовали погрешность, разность между полученным и желаемым результатами, для настройки классификатора.
Все те операции были достаточно простые, так как сама связь между погрешностью и величины, на которую надо было изменить коэффициент прямой оказалось очень простой.
Но как нам калибровать веса связей, когда на получаемый результат, а значит и на погрешность, влияют сразу несколько нейронов? Рисунок ниже демонстрирует проблему:

Очень легко работать с погрешностью, когда вход у нейрона всего один. Но сейчас уже два нейрона подают сигналы на два входа рассматриваемого нейрона. Что же делать с погрешностью?
Нет никакого смысла использовать погрешность целиком для корректировки одного веса, потому что в этом случае мы забываем про второй вес. Ведь оба веса задействованы в создании полученного результата, а значит оба веса виновны в итоговой погрешности.
Конечно, существует очень маленькая вероятность того, что только один вес внес погрешность, а второй был идеально откалиброван. Но даже если мы немного поменяем вес, который и так не вносит погрешность, то в процессе дальнейшего обучения сети он все равно придет в норму, так что ничего страшного.
Можно попытаться разделить погрешность одинаково на все нейроны:

Классная идея. Хотя я никогда не пробовал подобный вариант использования погрешности в реальных нейросетях, я уверен, что результаты вышли бы очень достойными.
Другая идея тоже заключается в разделении погрешности, но не поровну между всеми нейронами. Вместо этого мы кладем большую часть ответственности за погрешность на нейроны с большим весом связи. Почему? Потому что за счет своего большего веса они внесли больший вклад в выход нейрона, а значит и в погрешность.

На рисунке изображены два нейрона, которые подают сигналы третьему, выходному нейрону. Веса связей: \(3 \) и \(1 \) . Согласно нашей идее о переносе погрешности на нейроны мы используем \(\frac{3}{4} \) погрешности на корректировку первого (большего) веса и \(\frac{1}{4} \) на корректировку второго (меньшего) веса.
Идею легко развить до любого количества нейронов. Пусть у нас есть 100 нейронов и все они соединены с результирующим нейроном. В таком случае, мы распределяем погрешность на все 100 связей так, чтобы на каждую связь пришлась часть погрешности, соответствующая ее весу.
Как видно, мы используем веса связей для двух задач. Во-первых, мы используем веса в процессе распространения сигнала от входного до выходного слоя. Мы уже разобрались, как это делается. Во-вторых, мы используем веса для распространения ошибки в обратную сторону: от выходного слоя к входному. Из-за этого данный метод использования погрешности называют .
Если у нашей сети 2 нейрона выходного слоя, то нам пришлось бы использовать этот метод еще раз, но уже для связей, которые повлияли на выход второго нейрона выходного слоя. Рассмотрим эту ситуацию подробнее.
1.11 Обратное распространение ошибки от выходных нейронов
На диаграмме ниже изображена нейросеть с двумя нейронами во входном слое, как и в предыдущем примере. Но теперь у сети имеется два нейрона и в выходном слое.

Оба выхода сети могут иметь погрешность, особенно в тех случаях, когда сеть еще не натренирована. Мы должны использовать полученные погрешности для настройки весов связей. Можно использовать метод, который мы получили в предыдущем разделе - больше изменяем те нейроны, которые сделали больший вклад в выход сети.
То, что сейчас у нас больше одного выходного нейрона по сути ни на что не влияет. Мы просто используем наш метод дважды: для первого и второго нейронов. Почему так просто? Потому что связи с конкретным выходным нейроном никак не влияют на остальные выходные нейроны. Их изменение повлияет только на конкретный выходной нейрон. На диаграмме выше изменение весов \(w_{1,2} \) и \(w_{2,2} \) не повлияет на результат \(o_1 \) .
Погрешность первого нейрона выходного слоя мы обозначили за \(e_1 \) . Погрешность равна разнице между желаемым выходом нейрона \(t_1 \) , который мы имеем в обучающей выборке и полученным реальным результатом \(o_1 \) .
\[ e_1 = t_1 — o_1 \]
Погрешность второго нейрона выходного слоя равна \(e_2 \) .
На диаграмме выше погрешность \(e_1 \) разделяется на веса \(w_{1,1} \) и \(w_{2,1} \) соответственно их вкладу в эту погрешность. Аналогично, погрешность \(e_2 \) разделяется на веса \(w_{1,2} \) и \(w_{2,2} \) .
Теперь надо определить, какой вес оказал большее влияние на выход нейрона. Например, мы можем определить, какая часть ошибки \(e_1 \) пойдет на исправление веса \(w_{1,1} \) :
А вот так находится часть \(e_1 \) , которая пойдет на корректировку веса \(w_{2,1} \) :
\[ \frac{w_{2,1}}{w_{1,1} + w_{2,1}} \]
Теперь разберемся, что означают два этих выражения выше. Изначально наша идея заключается в том, что мы хотим сильнее изменить связи с большим весом и слегка изменить связи с меньшим весом.
А как нам понять величину веса относительно всех остальных весов? Для этого мы должны сравнить какой-то конкретный вес (например \(w_{1,1} \) ) с абстрактной «общей» суммой всех весов, повлиявших на выход нейрона. На выход нейрона повлияли два веса: \(w_{1,1} \) и \(w_{2,1} \) . Мы складываем их и смотрим, какая часть от общего вклада приходится на \(w_{1,1} \) с помощью деления этого веса на полученную ранее общую сумму:
\[ \frac{w_{1,1}}{w_{1,1}+w_{2,1}} \]
Пусть \(w_{1,1} \) в два раза больше, чем \(w_{2,1} \) : \(w_{1,1} = 6 \) и \(w_{2,1} = 3 \) . Тогда имеем \(6/(6+3) = 6/9 = 2/3 \) , а значит \(2/3 \) погрешности \(e_1 \) пойдет на корректировку \(w_{1,1} \) , а \(1/3 \) на корректировку \(w_{2,1} \) .
В случае, когда оба веса равны, то каждому достанется по половине погрешности. Пусть \(w_{1,1} = 4 \) и \(w_{2,1}=4 \) . Тогда имеем \(4/(4+4)=4/8=1/2 \) , а значит на каждый вес пойдет \(1/2 \) погрешности \(e_1 \) .
Прежде чем мы двинемся дальше, давайте на секунду остановимся и посмотрим, чего мы достигли. Нам нужно что-то менять в нейросети для уменьшения получаемой погрешности. Мы решили, что будем менять веса связей между нейронами. Мы также нашли способ, как распределять полученную на выходном слое сети погрешность между весами связей. В этом разделе мы получили формулы для вычисления конкретной части погрешности для каждого веса. Отлично!
Но есть еще одна проблема. Сейчас мы знаем, что делать с весами связей слое, который находится прямо перед выходным слоем сети. А что если наша нейросеть имеет больше 2 слоев? Что делать с весами связей в слоях, которые находятся за предпоследним слоем сети?
1.12 Обратное распространение ошибки на множество слоев
На диаграмме ниже изображена простая трехслойная нейросеть с входным, скрытым и выходным слоями.

Сейчас мы наблюдаем процесс, который обсуждался в разделе выше. Мы используем погрешность выходного слоя для настройки весов связей, которые соединяют предпоследний слой с выходным слоем.
Для простоты обозначения были обобщены. Погрешности нейронов выходного слоя мы в целом назвали \(e_{\text{out}} \) , а все веса связей между скрытым и выходным слоем обозначили за \(w_{\text{ho}} \) .
Еще раз повторю, что для корректировки весов \(w_{\text{ho}} \) мы распределяем погрешность нейрона выходного слоя по всем весам в зависимости от их вклада в выход нейрона.
Как видно из диаграммы ниже, для корректировки весов связей между входным и скрытым слоем нам надо повторить ту же операцию еще раз. Мы берем погрешности нейронов скрытого слоя \(e_{\text{hi}} \) и распределяем их по весам связей между входным и скрытым слоем \(w_{\text{ih}} \) :

Если бы у нас было бы больше слоев, то мы бы и дальше повторяли этот процесс корректировки, распространяющийся от выходного ко входному слою. И снова вы видите, почему этот способ называется методом обратного распространения ошибки .
Для корректировки связей между предпоследним и выходным слоем мы использовали погрешность выходов сети \(e_{\text{out}} \) . А чему же равна погрешность выходов нейронов скрытых слоев \(e_{\text{hi}} \) ? Это отличный вопрос потому что сходу на этот вопрос ответить трудно. Когда сигнал распространяется по сети от входного к выходному слою мы точно знаем значения выходных нейронов скрытых слоев. Мы получали эти значения с помощью функции активации, у которой в качестве аргумента использовалась сумма взвешенных сигналов, поступивших на вход нейрона. Но как из выходного значения нейрона скрытого слоя получить его погрешность?
У нас нет никаких ожидаемых или заранее подготовленных правильных ответов для выходов нейронов скрытого слоя. У нас есть готовые правильные ответы только для выходов нейронов выходного слоя. Эти выходы мы сравниваем с заранее правильными ответами из обучающей выборки и получаем погрешность. Давайте вновь проанализируем диаграмму выше.
Мы видим, что из первого нейрона скрытого слоя выходят две связи с двумя нейронами выходного слоя. В предыдущем разделе мы научились распределять погрешность на веса связей. Поэтому мы можем получить две погрешности для обоих весов этих связей, сложить их и получить общую погрешность данного нейрона скрытого слоя. Наглядная демонстрация:

Уже из рисунка можно понять, что делать дальше. Но давайте все-таки еще раз пройдемся по всему алгоритму. Нам нужно получить погрешность выхода нейрона скрытого слоя для того, чтобы скорректировать веса связей между текущим и предыдущим слоями. Назовем эту погрешность \(e_{\text{hi}} \) . Но мы не можем получить значение погрешности напрямую. Погрешность равна разности между ожидаемым и полученным значениями, но проблема заключается в том, что у нас есть ожидаемые значения только для нейронов выходного слоя нейросети.
В невозможности прямого нахождения погрешности нейронов скрытого слоя и заключается основная сложность.
Но выход есть. Мы умеем распределять погрешность нейронов выходного слоя по весам связей. Значит на каждый вес связи идет часть погрешности. Поэтому мы складываем части погрешностей, которые относятся к весам связей, исходящих из данного скрытого нейрона. Полученная сумма и будем считать за погрешность выхода данного нейрона. На диаграмме выше часть погрешности \(e_{\text{out 1}} \) идет на вес \(w_{1,1} \) , а часть погрешности \(e_{\text{out 2}} \) идет на вес \(w_{1,2} \) . Оба этих веса относятся к связям, исходящим из первого нейрона скрытого слоя. А значит мы можем найти его погрешность:
\[ e_{\text{hi 1}} = \text{сумма частей погрешностей для весов } w_{1,1} \text{ и } w_{1,2} \]
\[ e_{\text{hi 1}} = \left(e_{\text{out 1}}\cdot\frac{w_{1,1}}{w_{1,1} + w_{2,1}}\right) + \left(e_{\text{out 2}}\cdot\frac{w_{1,2}}{w_{1,2} + w_{2,2}}\right) \]
Рассмотрим алгоритм на реальной трехслойной нейросети с двумя нейронами в каждом слое:

Давайте отследим обратное распространение одной ошибки/погрешности. Погрешность второго выходного нейрона равна \(0.5 \) и она распределяется на два веса. На вес \(w_{12} \) идет погрешность \(0.1 \) , а на вес \(w_{22} \) идет погрешность \(0.4 \) . Дальше у нас идет второй нейрон скрытого слоя. От него отходят две связи с весами \(w_{21} \) и \(w_{22} \) . На эти веса связей также распределяется погрешность как от \(e_1 \) , так и от \(e_2 \) . На вес \(w_{21} \) идет погрешность \(0.9 \) , а на вес \(w_{22} \) идет погрешность \(0.4 \) . Сумма этих погрешностей и дает нам погрешность выхода второго нейрона скрытого слоя: \(0.4 + 0.9 = 1.3 \) .
Но это еще не конец. Теперь надо распределить погрешность нейронов выходного слоя на веса связей между входным и скрытым слоями. Проиллюстрируем этот процесс дальнейшего распространения ошибки:

Ключевые моменты
- Обучение нейросетей заключается в корректировки весов связей. Корректировка зависит от погрешности - разности между ожидаемым ответом из обучающей выборки и реально полученным результатами.
- Погрешность для нейронов выходного слоя рассчитывается как разница между желаемым и полученным результатами.
- Однако, погрешность скрытых нейронов определить напрямую нельзя. Одно из популярных решений - сначала необходимо распределить известную погрешность на все веса связей, а затем сложить те части погрешностей, которые относятся к связям, исходящим из одного нейрона. Сумма этих частей погрешностей и будет являться общей погрешностью этого нейрона.
1.13 Обратное распространение ошибки и произведение матриц
А можно ли использовать матрицы для упрощения всех этих трудных вычислений? Они ведь помогли нам ранее, когда мы рассчитывали проход сигнала по сети от входного к выходному слою.
Если бы мы могли выразить обратное распространение ошибки через произведение матриц, то все наши вычисления разом бы уменьшились, а компьютер бы сделал всю грязную и повторяющуюся работу за нас.
Начинаем мы с самого конца нейросети - с матрицы погрешностей ее выходов. В примере выше у нас имеется две погрешности сети: \(e_1 \) и \(e_2 \) .
\[ \mathbf{E}_{\text{out}} = \left(\begin{matrix}e_1 \\ e_2\end{matrix}\right) \]
Теперь нам надо получить матрицу погрешностей выходов нейронов скрытого слоя. Звучит довольно жутко, поэтому давайте действовать по шагам. Из предыдущего раздела вы помните, что погрешность нейрона скрытого слоя высчитывается как сумма частей погрешностей весов связей, исходящих из этого нейрона.
Сначала рассматриваем первый нейрон скрытого слоя. Как было показано в предыдущем разделе, погрешность этого нейрона высчитывается так:
\[ e_{\text{hi 1}} = \left(e_1\cdot\frac{w_{11}}{w_{11} + w_{21}}\right) + \left(e_2\cdot\frac{w_{12}}{w_{12} + w_{22}}\right) \]
Погрешность второго нейрона скрытого слоя высчитывается так:
\[ e_{\text{hi 2}} = \left(e_1\cdot\frac{w_{21}}{w_{11} + w_{21}}\right) + \left(e_2\cdot\frac{w_{22}}{w_{12} + w_{22}}\right) \]
Получаем матрицу погрешностей скрытого слоя:
\[ \mathbf{E}_{\text{hid}} = \left(\begin{matrix}e_{\text{hid 1}} \\ e_{\text{hid 2}}\end{matrix}\right) = \left(\begin{matrix} e_1\cdot\dfrac{w_{11}}{w_{11} + w_{21}} \hspace{5pt} + \hspace{5pt} e_2\cdot\dfrac{w_{12}}{w_{12} + w_{22}} \\ e_1\cdot\dfrac{w_{21}}{w_{11} + w_{21}} \hspace{5pt} + \hspace{5pt} e_2\cdot\dfrac{w_{22}}{w_{12} + w_{22}} \end{matrix}\right) \]
Многие из вас уже заметили произведение матриц:
\[ \mathbf{E}_{\text{hid}} = \left(\begin{matrix} \dfrac{w_{11}}{w_{11} + w_{21}} & \dfrac{w_{12}}{w_{12} + w_{22}} \\ \dfrac{w_{21}}{w_{11} + w_{21}} & \dfrac{w_{22}}{w_{12} + w_{22}} \end{matrix}\right)\times \left(\begin{matrix} e_1 \\ e_2 \end{matrix}\right) \]
Таким образом, мы смогли выразить вычисление матрицы погрешностей нейронов выходного слоя через произведение матриц. Однако выражение выше получилось немного сложнее, чем мне хотелось бы.
В формуле выше мы используем большую и неудобную матрицу, в которой делим каждый вес связи на сумму весов, приходящих в данный нейрон. Мы самостоятельно сконструировали эту матрицу.
Было бы очень удобно записать произведение из уже имеющихся матриц. А имеются у нас только матрицы весов связей, входных сигналов и погрешностей выходного слоя.
К сожалению, формулу выше никак нельзя записать в мега-простом виде, который мы получили для прохода сигнала в предыдущих разделах. Вся проблема заключается в жутких дробях, с которыми трудно что-то поделать.
Но нам очень нужно получить простую формулу для удобного и быстрого расчета матрицы погрешностей.
Пора немного пошалить!
Вновь обратим взор на формулу выше. Можно заметить, что самым главным является умножение погрешности выходного нейрона \(e_n \) на вес связи \(w_{ij} \) , которая к этому выходному нейрону подсоединена. Чем больше вес, тем большую погрешность получит нейрон скрытого слоя. Эту важную деталь мы сохраняем. А вот знаменатели дробей служат лишь нормализующим фактором. Если их убрать, то мы лишимся масштабирования ошибки на предыдущие слои, что не так уж и страшно. Таким образом, мы можем избавиться от знаменателей:
\[ e_1\cdot \frac{w_{11}}{w_{11} + w_{21}} \hspace{5pt} \longrightarrow \hspace{5pt} e_1 \cdot w_{11} \]
Запишем теперь формулу для получения матрицы погрешностей, но без знаменателей в левой матрице:
\[ \mathbf{E}_{\text{hid}} = \left(\begin{matrix} w_{11} & w_{12} \\ w_{21} & w_{22} \end{matrix}\right)\times \left(\begin{matrix} e_1 \\ e_2 \end{matrix}\right) \]
Так гораздо лучше!
В разделе по использованию матриц при расчетах прохода сигнала по сети мы использовали следующую матрицу весов:
\[ \left(\begin{matrix} w_{11} & w_{21} \\ w_{12} & w_{22} \end{matrix}\right) \]
Сейчас, для расчета матрицы погрешностей мы используем такую матрицу:
\[ \left(\begin{matrix} w_{11} & w_{12} \\ w_{21} & w_{22} \end{matrix}\right) \]
Можно заметить, что во второй матрице элементы как бы отражены относительно диагонали матрицы, идущей от левого верхнего до правого нижнего края матрицы: \(w_{21} \) и \(w_{12} \) поменялись местами. Такая операция над матрицами существует и называется она \textbf{транспонированием} матрицы. Ранее мы использовали матрицу весов \(\mathbf{W} \) . Транспонированные матрицы имеют специальный значок справа сверху: \(^\intercal \) . В расчете матрицы погрешностей мы используем транспонированную матрицу весов: \(\mathbf{W}^\intercal \) .
Вот два примера для иллюстрации транспонирования матриц. Заметьте, что данную операцию можно выполнять даже для матриц, в которых число столбцов и строк различно.
\[ \left(\begin{matrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{matrix}\right)^\intercal = \left(\begin{matrix} 1 & 4 & 7 \\ 2 & 5 & 8 \\ 3 & 6 & 9 \end{matrix}\right) \]
\[ \left(\begin{matrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{matrix}\right)^\intercal = \left(\begin{matrix} 1 & 4 \\ 2 & 5 \\ 3 & 6 \end{matrix}\right) \]
Мы получили то, что хотели - простую формулу для расчета матрицы погрешностей нейронов скрытого слоя:
\[ \mathbf{E}_{\text{hid}} = \mathbf{W}^\intercal \times \mathbf{E}_{\text{out}} \]
Это все конечно отлично, но правильно ли мы поступили, просто проигнорировав знаменатели? Да.
Дело в том, что сеть обучается не мгновенно, а проходит через множество шагов обучения. Таким образом она постепенно калибрует и корректирует собственные веса до приемлемого значения. Поэтому способ, с помощью которого мы находим погрешность не так важен. Я уже упоминал ранее, что мы могли бы разделить всю погрешность просто пополам между всеми весами, вносящими вклад в выход нейрона и даже тогда, по окончанию обучения, сеть выдавала бы неплохие результаты.
Безусловно, игнорирование знаменателей повлияет на процесс обучения сети, но рано или поздно, через сотни и тысячи шагов обучения, она дойдет до правильных результатов что со знаменателями, что без них.
Убрав знаменатели, мы сохранили общую суть обратного распространения ошибки - чем больше вес, тем больше его надо скорректировать. Мы просто убрали смягчающий фактор.
Ключевые моменты
- Обратное распространение ошибки может быть выражено через произведение матриц.
- Это позволяет нам удобно и эффективно производить расчеты вне зависимости от размеров нейросети.
- Получается что и прямой проход сигнала по нейросети и обратно распространение ошибки можно выразить через матрицы с помощью очень похожих формул.
Сделайте перерыв. Вы его заслужили. Следующие несколько разделов будут финальными и очень крутыми. Но их надо проходить на свежую голову.
Ошибки от выходов сети к её входам, в направлении, обратном прямому распространению сигналов в обычном режиме работы. Барцев и Охонин предложили сразу общий метод («принцип двойственности »), приложимый к более широкому классу систем, включая системы с запаздыванием, распределённые системы , и т. п.
Для возможности применения метода обратного распространения ошибки передаточная функция нейронов должна быть дифференцируема . Метод является модификацией классического метода градиентного спуска .
Сигмоидальные функции активации
Наиболее часто в качестве функций активации используются следующие виды сигмоид :
Функция Ферми (экспоненциальная сигмоида):
Рациональная сигмоида:
Гиперболический тангенс:
,где s - выход сумматора нейрона, - произвольная константа.
Менее всего, сравнительно с другими сигмоидами, процессорного времени требует расчет рациональной сигмоиды. Для вычисления гиперболического тангенса требуется больше всего тактов работы процессора. Если же сравнивать с пороговыми функциями активации, то сигмоиды рассчитываются очень медленно. Если после суммирования в пороговой функции сразу можно начинать сравнение с определенной величиной (порогом), то в случае сигмоидальной функции активации нужно рассчитать сигмоид (затратить время в лучшем случае на три операции: взятие модуля, сложение и деление), и только потом сравнивать с пороговой величиной (например, нулём). Если считать, что все простейшие операции рассчитываются процессором за примерно одинаковое время, то работа сигмоидальной функции активации после произведённого суммирования (которое займёт одинаковое время) будет медленнее пороговой функции активации как 1:4.
Функция оценки работы сети
В тех случаях, когда удается оценить работу сети, обучение нейронных сетей можно представить как задачу оптимизации. Оценить - означает указать количественно, хорошо или плохо сеть решает поставленные ей задачи. Для этого строится функция оценки. Она, как правило, явно зависит от выходных сигналов сети и неявно (через функционирование) - от всех её параметров. Простейший и самый распространенный пример оценки - сумма квадратов расстояний от выходных сигналов сети до их требуемых значений:
,где - требуемое значение выходного сигнала.
Описание алгоритма

Архитектура многослойного перцептрона
Алгоритм обратного распространения ошибки применяется для многослойного перцептрона . У сети есть множество входов , множество выходов Outputs и множество внутренних узлов. Перенумеруем все узлы (включая входы и выходы) числами от 1 до N (сквозная нумерация, вне зависимости от топологии слоёв). Обозначим через вес, стоящий на ребре, соединяющем i-й и j-й узлы, а через - выход i-го узла. Если нам известен обучающий пример (правильные ответы сети , ), то функция ошибки, полученная по методу наименьших квадратов , выглядит так:
Как модифицировать веса? Мы будем реализовывать стохастический градиентный спуск , то есть будем подправлять веса после каждого обучающего примера и, таким образом, «двигаться» в многомерном пространстве весов. Чтобы «добраться» до минимума ошибки, нам нужно «двигаться» в сторону, противоположную градиенту , то есть, на основании каждой группы правильных ответов, добавлять к каждому весу
,где - множитель, задающий скорость «движения».
Производная считается следующим образом. Пусть сначала , то есть интересующий нас вес входит в нейрон последнего уровня. Сначала отметим, что влияет на выход сети только как часть суммы , где сумма берется по входам j-го узла. Поэтому
Аналогично, влияет на общую ошибку только в рамках выхода j-го узла (напоминаем, что это выход всей сети). Поэтому
Если же j-й узел - не на последнем уровне, то у него есть выходы; обозначим их через Children(j). В этом случае
, .Ну а - это в точности аналогичная поправка, но вычисленная для узла следующего уровня будем обозначать ее через - от она отличается отсутствием множителя . Поскольку мы научились вычислять поправку для узлов последнего уровня и выражать поправку для узла более низкого уровня через поправки более высокого, можно уже писать алгоритм. Именно из-за этой особенности вычисления поправок алгоритм называется алгоритмом обратного распространения ошибки (backpropagation). Краткое резюме проделанной работы:
- для узла последнего уровня
- для внутреннего узла сети
- для всех узлов
Получающийся алгоритм представлен ниже. На вход алгоритму, кроме указанных параметров, нужно также подавать в каком-нибудь формате структуру сети. На практике очень хорошие результаты показывают сети достаточно простой структуры, состоящие из двух уровней нейронов - скрытого уровня (hidden units) и нейронов-выходов (output units); каждый вход сети соединен со всеми скрытыми нейронами, а результат работы каждого скрытого нейрона подается на вход каждому из нейронов-выходов. В таком случае достаточно подавать на вход количество нейронов скрытого уровня.
Алгоритм
Алгоритм: BackPropagation
где - коэффициент инерциальнности для сглаживания резких скачков при перемещении по поверхности целевой функции
Математическая интерпретация обучения нейронной сети
На каждой итерации алгоритма обратного распространения весовые коэффициенты нейронной сети модифицируются так, чтобы улучшить решение одного примера. Таким образом, в процессе обучения циклически решаются однокритериальные задачи оптимизации.
Обучение нейронной сети характеризуется четырьмя специфическими ограничениями, выделяющими обучение нейросетей из общих задач оптимизации: астрономическое число параметров, необходимость высокого параллелизма при обучении, многокритериальность решаемых задач, необходимость найти достаточно широкую область, в которой значения всех минимизируемых функций близки к минимальным. В остальном проблему обучения можно, как правило, сформулировать как задачу минимизации оценки. Осторожность предыдущей фразы («как правило») связана с тем, что на самом деле нам неизвестны и никогда не будут известны все возможные задачи для нейронных сетей, и, быть может, где-то в неизвестности есть задачи, которые несводимы к минимизации оценки. Минимизация оценки - сложная проблема: параметров астрономически много (для стандартных примеров, реализуемых на РС - от 100 до 1000000), адаптивный рельеф (график оценки как функции от подстраиваемых параметров) сложен, может содержать много локальных минимумов.
Недостатки алгоритма
Несмотря на многочисленные успешные применения обратного распространения, оно не является панацеей. Больше всего неприятностей приносит неопределённо долгий процесс обучения. В сложных задачах для обучения сети могут потребоваться дни или даже недели, она может и вообще не обучиться. Причиной может быть одна из описанных ниже.
Паралич сети
В процессе обучения сети значения весов могут в результате коррекции стать очень большими величинами. Это может привести к тому, что все или большинство нейронов будут функционировать при очень больших значениях OUT, в области, где производная сжимающей функции очень мала. Так как посылаемая обратно в процессе обучения ошибка пропорциональна этой производной, то процесс обучения может практически замереть. В теоретическом отношении эта проблема плохо изучена. Обычно этого избегают уменьшением размера шага η, но это увеличивает время обучения. Различные эвристики использовались для предохранения от паралича или для восстановления после него, но пока что они могут рассматриваться лишь как экспериментальные.
Локальные минимумы
Обратное распространение использует разновидность градиентного спуска , то есть осуществляет спуск вниз по поверхности ошибки, непрерывно подстраивая веса в направлении к минимуму. Поверхность ошибки сложной сети сильно изрезана и состоит из холмов, долин, складок и оврагов в пространстве высокой размерности. Сеть может попасть в локальный минимум (неглубокую долину), когда рядом имеется гораздо более глубокий минимум. В точке локального минимума все направления ведут вверх, и сеть неспособна из него выбраться. Основную трудность при обучении нейронных сетей составляют как раз методы выхода из локальных минимумов: каждый раз выходя из локального минимума снова ищется следующий локальный минимум тем же методом обратного распространения ошибки до тех пор, пока найти из него выход уже не удаётся.
Размер шага
Внимательный разбор доказательства сходимости показывает, что коррекции весов предполагаются бесконечно малыми. Ясно, что это неосуществимо на практике, так как ведёт к бесконечному времени обучения. Размер шага должен браться конечным. Если размер шага фиксирован и очень мал, то сходимость слишком медленная, если же он фиксирован и слишком велик, то может возникнуть паралич или постоянная неустойчивость. Эффективно увеличивать шаг до тех пор, пока не прекратится улучшение оценки в данном направлении антиградиента и уменьшать, если такого улучшения не происходит. П. Д. Вассерман описал адаптивный алгоритм выбора шага, автоматически корректирующий размер шага в процессе обучения. В книге А. Н. Горбаня предложена разветвлённая технология оптимизации обучения.
Следует также отметить возможность переобучения сети, что является скорее результатом ошибочного проектирования её топологии. При слишком большом количестве нейронов теряется свойство сети обобщать информацию. Весь набор образов, предоставленных к обучению, будет выучен сетью, но любые другие образы, даже очень похожие, могут быть классифицированы неверно.
См. также
- Алгоритм скоростного градиента
Литература
- Уоссермен Ф. Нейрокомпьютерная техника: Теория и практика . - М .: «Мир», 1992.
- Хайкин С. Нейронные сети: Полный курс. Пер. с англ. Н. Н. Куссуль, А. Ю. Шелестова. 2-е изд., испр. - М.: Издательский дом Вильямс, 2008, 1103 с.
Ссылки
- Копосов А. И., Щербаков И. Б., Кисленко Н. А., Кисленко О. П., Варивода Ю. В. и др. . - М .: ВНИИГАЗ, 1995.
В первой части были рассмотрены: структура, топология, функции активации и обучающее множество. В этой части попробую объяснить как происходит обучение сверточной нейронной сети.
Обучение сверточной нейронной сети
На начальном этапе нейронная сеть является необученной (ненастроенной). В общем смысле под обучением понимают последовательное предъявление образа на вход нейросети, из обучающего набора, затем полученный ответ сравнивается с желаемым выходом, в нашем случае это 1 – образ представляет лицо, минус 1 – образ представляет фон (не лицо), полученная разница между ожидаемым ответом и полученным является результат функции ошибки (дельта ошибки). Затем эту дельту ошибки необходимо распространить на все связанные нейроны сети.Таким образом обучение нейронной сети сводится к минимизации функции ошибки, путем корректировки весовых коэффициентов синаптических связей между нейронами. Под функцией ошибки понимается разность между полученным ответом и желаемым. Например, на вход был подан образ лица, предположим, что выход нейросети был 0.73, а желаемый результат 1 (т.к. образ лица), получим, что ошибка сети является разницей, то есть 0.27. Затем веса выходного слоя нейронов корректируются в соответствии с ошибкой. Для нейронов выходного слоя известны их фактические и желаемые значения выходов. Поэтому настройка весов связей для таких нейронов является относительно простой. Однако для нейронов предыдущих слоев настройка не столь очевидна. Долгое время не было известно алгоритма распространения ошибки по скрытым слоям.
Алгоритм обратного распространения ошибки
Для обучения описанной нейронной сети был использован алгоритм обратного распространения ошибки (backpropagation). Этот метод обучения многослойной нейронной сети называется обобщенным дельта-правилом. Метод был предложен в 1986 г. Румельхартом, Макклеландом и Вильямсом. Это ознаменовало возрождение интереса к нейронным сетям, который стал угасать в начале 70-х годов. Данный алгоритм является первым и основным практически применимым для обучения многослойных нейронных сетей.Для выходного слоя корректировка весов интуитивна понятна, но для скрытых слоев долгое время не было известно алгоритма. Веса скрытого нейрона должны изменяться прямо пропорционально ошибке тех нейронов, с которыми данный нейрон связан. Вот почему обратное распространение этих ошибок через сеть позволяет корректно настраивать веса связей между всеми слоями. В этом случае величина функции ошибки уменьшается и сеть обучается.
Основные соотношения метода обратного распространения ошибки получены при следующих обозначениях:
Величина ошибки определяется по формуле 2.8 среднеквадратичная ошибка:

Неактивированное состояние каждого нейрона j для образа p записывается в виде взвешенной суммы по формуле 2.9:

Выход каждого нейрона j является значением активационной функции
Которая переводит нейрон в активированное состояние. В качестве функции активации может использоваться любая непрерывно дифференцируемая монотонная функция. Активированное состояние нейрона вычисляется по формуле 2.10:

В качестве метода минимизации ошибки используется метод градиентного спуска, суть этого метода сводится к поиску минимума (или максимума) функции за счет движения вдоль вектора градиента. Для поиска минимума движение должно быть осуществляться в направлении антиградиента. Метод градиентного спуска в соответствии с рисунком 2.7.
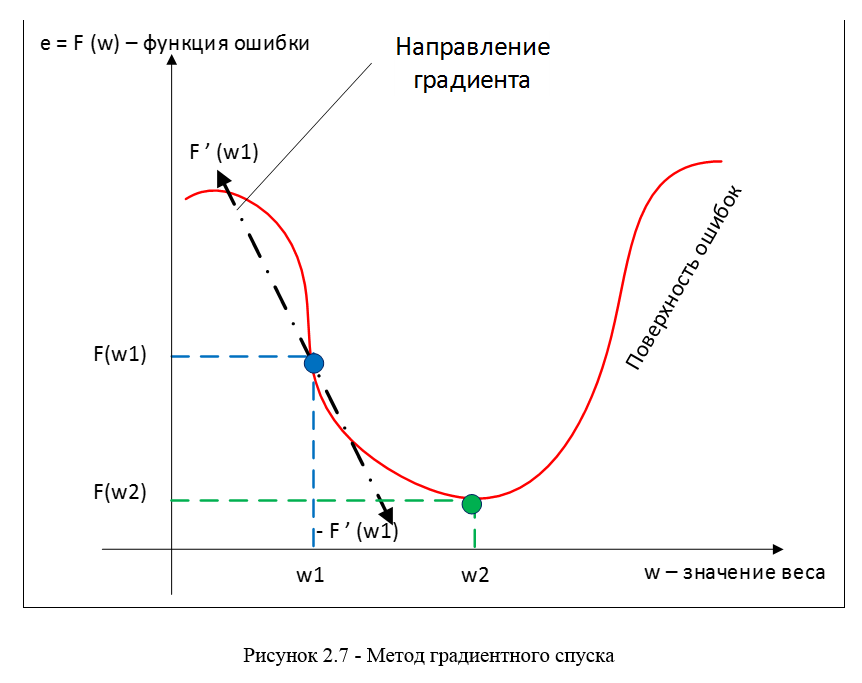
Градиент функции потери представляет из себя вектор частных производных, вычисляющийся по формуле 2.11:

Производную функции ошибки по конкретному образу можно записать по правилу цепочки, формула 2.12:

Ошибка нейрона обычно записывается в виде символа δ (дельта). Для выходного слоя ошибка определена в явном виде, если взять производную от формулы 2.8, то получим t минус y , то есть разницу между желаемым и полученным выходом. Но как рассчитать ошибку для скрытых слоев? Для решения этой задачи, как раз и был придуман алгоритм обратного распространения ошибки. Суть его заключается в последовательном вычислении ошибок скрытых слоев с помощью значений ошибки выходного слоя, т.е. значения ошибки распространяются по сети в обратном направлении от выхода к входу.
Ошибка δ для скрытого слоя рассчитывается по формуле 2.13:
Алгоритм распространения ошибки сводится к следующим этапам:
- прямое распространение сигнала по сети, вычисления состояния нейронов;
- вычисление значения ошибки δ для выходного слоя;
- обратное распространение: последовательно от конца к началу для всех скрытых слоев вычисляем δ по формуле 2.13;
- обновление весов сети на вычисленную ранее δ ошибки.

До этого момента были рассмотрены случаи распространения ошибки по слоям персептрона, то есть по выходному и скрытому, но помимо них, в сверточной нейросети имеются подвыборочный и сверточный.
Расчет ошибки на подвыборочном слое
Расчет ошибки на подвыборочном слое представляется в нескольких вариантах. Первый случай, когда подвыборочный слой находится перед полносвязным, тогда он имеет нейроны и связи такого же типа, как в полносвязном слое, соответственно вычисление δ ошибки ничем не отличается от вычисления δ скрытого слоя. Второй случай, когда подвыборочный слой находится перед сверточным, вычисление δ происходит путем обратной свертки. Для понимания обратно свертки, необходимо сперва понять обычную свертку и то, что скользящее окно по карте признаков (во время прямого распространения сигнала) можно интерпретировать, как обычный скрытый слой со связями между нейронами, но главное отличие - это то, что эти связи разделяемы, то есть одна связь с конкретным значением веса может быть у нескольких пар нейронов, а не только одной. Интерпретация операции свертки в привычном многослойном виде в соответствии с рисунком 2.8.
Рисунок 2.8 - Интерпретация операции свертки в многослойный вид, где связи с одинаковым цветом имеют один и тот же вес. Синим цветом обозначена подвыборочная карта, разноцветным – синаптическое ядро, оранжевым – получившаяся свертка
Теперь, когда операция свертки представлена в привычном многослойном виде, можно интуитивно понять, что вычисление дельт происходит таким же образом, как и в скрытом слое полносвязной сети. Соответственно имея вычисленные ранее дельты сверточного слоя можно вычислить дельты подвыборочного, в соответствии с рисунком 2.9.
Рисунок 2.9 - Вычисление δ подвыборочного слоя за счет δ сверточного слоя и ядра
Обратная свертка
– это тот же самый способ вычисления дельт, только немного хитрым способом, заключающийся в повороте ядра на 180 градусов и скользящем процессе сканирования сверточной карты дельт с измененными краевыми эффектами. Простыми словами, нам необходимо взять ядро сверточной карты (следующего за подвыборочным слоем) повернуть его на 180 градусов и сделать обычную свертку по вычисленным ранее дельтам сверточной карты, но так чтобы окно сканирования выходило за пределы карты. Результат операции обратной свертки в соответствии с рисунком 2.10, цикл прохода обратной свертки в соответствии с рисунком 2.11.
Рисунок 2.10 - Результат операции обратной свертки

Рисунок 2.11 - Повернутое ядро на 180 градусов сканирует сверточную карту